Table of Contents
Summer Institutes in Computational Social Science 2020 Post-mortem
Published on: August 19, 2020
We’ve just completed the 2020 Summer Institutes in Computational Social Science. The purpose of the Summer Institutes is to bring together graduate students, postdoctoral researchers, and beginning faculty interested in computational social science. The Summer Institutes are for both social scientists (broadly conceived) and data scientists (broadly conceived). This summer all of our Institutes were virtual because of COVID-19, but we will still refer to them by their planned physical location. In addition to SICSS-Duke, which was organized by Chris Bail and Matthew Salganik, there were 7 partner locations run by SICSS alumni.
- SICSS-Bay Area organized by Jae Yeon Kim (SICSS-Princeton 19), Jaren Haber (SICSS-Princeton 19), and Nick Camp (SICSS-Princeton 19).
- SICSS-Istanbul organized by Akın Ünver (SICSS-Kadir Has University 19) and Matti Nelimarkka (SICSS-Kadir Has University 19, SICSS-Helsinki 18, SICSS-Princeton 17)
- SICSS-Maastricht organized by Monika Leszczyńska (SICSS-Princeton 19) and Catalina Goanta
- SICSS-Montreal organized by Vissého Adjiwanou (SICSS-Cape Town 18, 19, SICSS-Princeton 17) and Julie Hussin
- SICSS-Rutgers organized by Katherine McCabe (SICSS-Princeton 19), Hana Shepherd, and Kira Sanbonmatsu
- SICSS-Stellenbosch organized by Aldu Cornelissen (SICSS-Cape Town 18), Douglas Parry (SICSS-Cape Town 19), and Richard Barnett (SICSS-Cape Town 18)
- WICSS-Tucson organized by Thomas Davidson (SICSS-Princeton 19) and Yotam Shmargad
- SICSS-UCLA organized by Alina Arseniev-Koehler (SICSS-University of Washington 18, SICSS-UCLA 19), Jennie E. Brand (SICSS-UCLA 19), Pablo Geraldo Bastías (SICSS-UCLA 19), and Bernard Koch (SICSS-UCLA 19)
In addition to the locations that happened virtually, we have 13 locations postponed because of COVID: SICSS-Beijing, SICSS-Chicago, SICSS-Copenhagen, SICSS-HSE University, SICSS-Helsinki, SICSS-Howard-Mathematica, SICSS-Konstanz, SICSS-Milano, SICSS-NYU, SICSS-Oxford, SICSS-Paris, SICSS-Princeton-CITP, and SICSS-Tokyo.
The purpose of this blog post is to describe a) what we did, b) what we think worked well, and c) what we will do differently next time. We hope that this document will be useful to other people organizing similar Summer Institutes, as well as people who are organizing partner locations for the 2021 Summer Institutes in Computational Social Science. If you are interested in hosting a partner location of SICSS 2021 at your university, company, NGO, or governmental organization, please read our information for potential partner locations.
This post includes post-mortem reports from all of our locations in order to facilitate comparisons. As you will see, different sites did things differently, and think that this kind of customization was an important part of how we were successful.
SICSS-Duke organized by Chris Bail and Matthew Salganik
We’ve divided this post into 7 main sections: 1) outreach and application process; 2) pre-arrival and onboarding; 3) pre-recording of lectures; 4) first week; 5) second week (group projects); 6) second week (SICSS Festival); 7) post-departure.
1. Outreach and application process
We continue to think that the best way to have a great Summer Institute is to have great participants. As in previous years, we advertised our event to a large, diverse group Our major outreach effort began in January— once almost all of the partner locations had been finalized. We emailed former participants and former speakers. We also advertised through professional societies and asked our funders to help spread the word. Finally, we tried to reach potentially interested participants through social media, email lists, and emails to faculty that we thought might know interested participants. We made a special effort to reach out to faculty that we thought might know people from groups that are under-represented in our applicant pool. We were happy to learn that this year many participants heard about the Summer Institutes from a former participant.
Managing the application process was better this year than last year. In 2019, at the request of our funder, the Russell Sage Foundation (RSF), we switched to Fluxx (partner locations are not required to use Fluxx and are not allowed to use the RSF instance of Fluxx). Based on what we learned in 2019, we improved the process and it went pretty smoothly. A key change was looping in staff at RSF when there were problems with Fluxx. It was particularly helpful for there to be a specific person at RSF for the TA on application support to message when applicants had issues with their submissions. One challenge that has come up in all three years is the difficulty of accepting letters of reference. This always proves one of the most logistically difficult parts, and we would urge locations to consider these costs when contemplating requesting letters.
We received all of our applications before COVID, and we did our selection of candidates before we knew that the event would be virtual. After we decided that we would have SICSS-Duke and that it would be virtual, we informed applicants that they were accepted and the event would be virtual. We were quite happy that our yield was close to 100%.
When selecting participants, we did not consider what time zone they lived in. But, time zones turned out to be a barrier for some participants. All of our events were based on Eastern Time US (the timezone of Duke). Most of our participants were located between Pacific Time US and Eastern Time US, and they could take part without much difficulty. A few participants were located in Europe, and talks that happened in the evenings (Eastern Time US) were harder for them to attend. One participant was based in Australia, and this made it very difficult for him to fully participate. One of the participants we admitted who lives in Asia decided not to participate because of the time change.
2. Pre-arrival and onboarding
After participants are accepted we begin to onboard them into the program and provide them with pre-arrival materials. The goal is to have them arrive at SICSS ready to learn.
We added all participants and staff to a Google group and sent out an email to the group requesting participant bio information for our website and providing participants information on pre-arrival logistics, such as how to join the Slack workspace. To collect information from participants, we used a Google form that we linked to in the email.
On the Google form, we asked for:
- name (as it should be displayed on the website)
- personal website link, if desired
- short bio for the website
- photo to display on the website
- previous coding experience
- preferred contact email
- preferred T-shirt size
The use of one Google form minimizes the number of emails.
In addition to requesting this information, the email reminded participants to read the pre-arrival section of the website, gave them a link to use to join the SICSS 2020 Slack workspace, requested that they join the #sicss-duke and #pre-office-hours channels, gave some additional detail about videoconference plans and linked to an article providing tips for improving their experience with Zoom, and requested T-shirt designs.
After sending email reminders to a handful of participants, eventually everyone completed the Google form. A few participants never submitted profile pictures.
Unfortunately, we forgot to ask for a T-shirt shipping address, so we sent out an additional form the week before the event to collect the shipping address and shirt size (again). This form went to participants at all SICSS locations. In future, if we are shipping shirts individually, we should ask for the shipping address in the original onboarding form, using a template that is friendly to international addresses (the defaults for this in Google Forms can be US-specific). The vendor used for US/Canada shipping was createmytee.com and for International was customink.com.
T-shirts are a SICSS tradition, and we think they are a great way to build community. Because the event was virtual this year, we shipped t-shirts to each individual participant who requested one. This ended up being a lot of logistical work and a fairly high financial cost. While t-shirt vendors are increasingly adding the capability of bulk ordering with individual shipping, there was not a large selection, and there was a flat shipping fee added for each individual. Additionally, very few vendors were able to ship individually internationally. To try to accommodate these issues while staying close to budget, we ordered t-shirts from two vendors – one for all participants living in the US and Canada, and another for participants who live outside of the US and Canada. The website for the US vendor (createmytee) said on their website that there was “always free shipping.” This was not actually true in the case of individual shipping.
To avoid these issues in the future, we should aim to have an estimate of the number of people who want a shirt and their locations at least 2 weeks before the actual event so the logistics can be worked out prior to event responsibilities. To help with issues of international/national shipping, one possibility could be having a central t-shirt design and then having site organizers be in charge of placing orders for participants attending their site.
Another component of the pre-arrival support is office hours run by our TAs. These office hours are open to participants at all SICSS locations. We provided 6 weeks of office hours from 5 TAs. We tried to spread out different times so that people from different time zones can attend at least one if needed. Few attended the sessions. But for the ones who attended, TAs were able to help them set up R and discuss potential project ideas.
3. Pre-recording of lectures
One major change this year is that we switched to a “flipped classroom” model, which required us to pre-record our lectures. We decided that the quality of these videos was important so we invested a lot of work into making them high-quality. This was a huge amount of work, but participants reported that they turned out well. The work mainly consisted of two parts. First, the lectures needed to be modified to fit into smaller chunks. All the advice we received was that they should be no longer than 30 minutes. Second, and even more time consuming, was the need to get equipment and actually record them. We each used a high-quality camera, three lights, a high-quality green screen, and a lav mic. Getting this equipment during the early stages of the pandemic was challenging, and it was time consuming to set-up and learn how to use it correctly. We also found it much harder lecturing to a camera than lecturing to a live room of participants. We worked with a professional videographer, Corey Reid, and he helped us so much, including recommending equipment, helping us set it up, and then editing the final videos. We are grateful to Corey and if you are looking to produce some videos like ours and you are looking for help, you should get in touch with Corey.
One challenge for Matt is that much of his lecture materials overlaps with his book Bit by Bit: Social Research in the Digital Age. After a bunch of deliberation, Matt decided to restructure his lectures so that the material from Bit by Bit was separated from the additions and extensions. For the areas of overlaps, participants could watch the video, read the book, or both. For the additions and extensions, they had to watch the videos. Ultimately, we think this was the right choice, but we could have explained it more clearly to our participants.
Week 1
The first week of SICSS is traditionally a mix of lectures and group activities. This year, to reduce Zoom fatigue, we pre-recorded our lectures and asked participants to watch them before arriving. We also reduced the length of the day (e.g., starting at 10am rather than 9am), added more breaks, reduced the number of guest speakers, and made more events optional. Overall, we think these changes were necessary and reasonably effective.
We began the first week with a virtual meet-and-greet on Sunday evening, largely following this model. We encouraged participants to read each other’s bios before the event. After a few words from Chris, participants and staff were randomized into groups of four for 30 minutes, then randomized into a different group of four for another 30 minutes. There was a final optional 30-minute interval. Feedback on this structure was quite positive. Groups of four seemed to be roughly the right size.
We used several different models during the 5 days of instruction, and we received different feedback on different days. It is hard to know how much of the results were attributed to our instructional choices, as opposed to the content of the day, the fact that participants were getting more familiar with Zoom and each other, and the fact that participants were generally getting more exhausted. All days followed a structure where participants were split into smaller groups to work together on activities (which are all available from our website). What differed across days was how open-ended the activities were, how multi-dimensional the activities were (i.e., did they require a mix of skills or just a single skill), the sizes of the groups (between 3 and 5), how the groups were formed (e.g., random or designed to be mixed skills), and whether we came back together at the end of the day for participants to share and discuss what they did in their smaller groups. It is not clear if there are right answers to any of these decisions, but we think that each should be made explicitly based on the learning objectives for that day.
As expected, collaboration over Zoom proved tricky, especially for activities that required coding collaboratively. Different groups experimented with different ways to navigate this, including screen sharing, working individually and passing files back and forth to one another, and controlling each others’ computers via Zoom remote control. Using Zoom remote control requires users to grant Zoom security and privacy access in accessibility (MacOS). This requires allowing others to control a user’s computer, which we viewed as a potential serious limitation. None of these solutions are ideal. It would be preferable to find a platform to facilitate real-time collaborative code editing. We think screen.so may hold promise in this regard. Similar to remote control via Zoom, screen.so requires privacy access but users can specify the window that other users can have control. Remote control does not address the issue of having incompatible computing environments. There were many other tools, but unfortunately we were unable to find another service that was both free and allowed for collaborative, real-time group editing. We also tested RStudio Cloud, which does not allow real-time group editing, and CoCalc, which only allows real-time group editing with a paid subscription. No participants opted to try screen.so or the other collaborative platforms. Most groups simply shared screens, but we received feedback from some participants that this format encouraged the most experienced coders to take over, and made it difficult for less experienced coders to participate.
As with events in person, it was difficult in the virtual format to ensure a relatively equal balance of participation. Sometimes a small number of people dominated the discussion and other people did not participate. We received a few comments about this issue in the keep-start-stop surveys throughout week 1. It seemed to be an issue in both breakout rooms and large group settings. Smaller groups (e.g., 3 people) and more structured activities seemed to mitigate these problems somewhat. Another challenge to shared participation was the choice of programming language. Most participants prefer R and some Python. We did not choose to separate people based on their preferred languages. One reason is that collaboration in computational social science may involve people working together using tools they’re not familiar with.
For many events, we used Zoom breakout rooms for small group work. Creating random breakout rooms in Zoom is quite easy, and making other instructors co-hosts let them move between rooms. However, if someone leaves the Zoom call and then comes back, Zoom does not remember what room they were in. Internet connectivity issues occasionally caused participants to leave and then come back, and the TA who was the host of each meeting could easily re-assign them to the correct room. However, after lunch breaks everyone would come back at once, which caused some delay in getting everyone back into their rooms because they all had to be re-assigned. When an instructor took some time at the start of the post-lunch session to set up the next part of the activity, this delay was less noticeable for the participants. Something we could have done pre-arrival to make this process easier was to collect the email address each participant uses for Zoom. This address is often a university-set field, so is sometimes different from the email they give us for regular communication. With preset breakout rooms using those emails, groups can be re-formed instantaneously to ease transition coming back from lunch.
At an in-person SICSS a lot of learning and community building happens in lunches. To mimic the experience of sharing meals with fellow participants, we opened a few breakout rooms from 12-1 each day in Week 1. We selected a conversation topic for each room beforehand from suggestions participants gave in Slack. We made all participants co-hosts of the Zoom meeting so that they could move between rooms at will. One room was always devoted to non-academic topics. Many of the suggested topics were very generative. To prevent Zoom fatigue, we made attending the lunch conversations optional. Attendance was highest on the first day and dropped thereafter. On some days, participants coalesced on just one of the rooms, leaving in effect just one topic. We found that having TAs evenly distribute between rooms at the start of lunch mitigated this issue somewhat.
Week 2 (Group Projects)
A major part of SICSS is participant-led group research projects during the second week. This year, because of the online nature of the event and the challenging nature of the times, we decided to make the group projects optional.
In our research group matching process, we used a google spreadsheet for people to add research interests. As people are adding their research interests live, we need a way of telling people to stop adding research interests, and to make sure they add zeros and ones to all of the cells. To do this, it would be more effective to have everyone in the same zoom at the beginning of this exercise.
It is much more difficult to keep track of group projects in a virtual setting. Though we had a list of project ideas and very tentative group assignments from early in the week, this changed substantially through the week in ways that were difficult to track. By the end of the week, we were no longer sure how many participants were participating in group projects, and we were much more aware of some projects than others. Some groups remained on the scheduled Zoom link to be in the breakout rooms. Some met separately. This made it difficult to check in with groups and provide them support. In future, we should ask participants to record which group they ended up joining and provide a short description of what that group is doing, perhaps on Tuesday, after this is mostly settled or perhaps at the end of each day. This way we can be sure to check in with all active groups on a more regular basis.
Running the group projects through one central MTurk worked although it was somewhat difficult to coordinate times when everyone was available to set up and run the HIT. In the future, if one person is going to run several projects through a central MTurk account, a possibility could be making a Google Form for research groups to submit: the link to their survey, the name and description of their survey, the number of participants, the payment they want per participant, and any restrictions on participants. In this way, the person running the MTurk could have all that information on hand when running the HIT for the participants without having to find a time to screen-share on zoom or constantly messaging on Slack.
One other question that came up several times was how IRB approval works with small research projects. Pre-empting the confusion around IRB, in the future we should state clearly the expectations at the end of research speed dating and on the second day is a good idea.
Creating an MTurk/Prolific account and linked gmail account for each site and depositing a set amount of research funds that site organizers could use at their discretion worked well. Having them set up in the week prior to the event in the future would likely be helpful, just in easing communication and ensuring everyone can access the account prior to the event.
Some groups at the Duke site were also interested in doing research not on MTurk. Looking into using Prolific more broadly could be one option or making it clear the types of funds we can accommodate versus not accommodate.
On Friday there were three groups presenting their group projects. While only half of the attendees were involved in one of the three projects, around twenty attendees attended the closing presentation and gave thoughtful feedback.
Week 2 (SICSS Festival)
This year we launched the first-ever SICSS Festival. During the Festival, alumni from all SICSS locations hosted events such as tutorials and panel discussions. With the Festival we were hoping to provide learning opportunities to a larger and more diverse set of people than those who can commit to attending a two week long program. We also wanted to provide an opportunity to showcase the contributions and expertise of our amazing alumni.
Initially, we decided to try to host about 5 events (one per day) in order to cover a range of topics and also not spread our audience too thin. The SICSS-Duke organizers and Festival organizers worked together to brainstorm panel ideas that would feature alumni. Then we emailed alumni that we knew were passionate about these topics asking them if they wanted to participate. In all cases the alumni said yes, and sometimes they even suggested other alumni to include. Once all panelists agreed, we created a shared google doc for each panel where we participants could comment on the proposed description, suggest questions, and leave notes. Having one google doc that held all the information about each event was a good structure and preventing things from getting lost in email. After we announced the Festival to the SICSS alumni, we received additional proposals for panels. In the end we hosted about 10 events.
Many panels could be split into about 5 chunks. In the initial chunk the moderator kicked off the event. This kick-off often included: telling the audience about SICSS and the SICSS Festival, providing a rough schedule for the event, providing information about how and when the audience can ask questions (we used both a mix of chat, video, and Zoom’s Q&A feature depending on the event), a reminder that the event is being recorded (if applicable), and a bio of the speaker. The second chunk of the panel involved the moderator and panelists in conversation. The third chunk involved the transition to audience questions. The forth chunk involved audience questions. The fifth chunk involved wrapping up, including thanking everyone, reminding them that they will receive a feedback form that we will share with the speaker, and reminding them about upcoming events. In some panels, we created a 10-15 minutes informal conversation time during which we have stopped recording. This provided a space for some attendees to talk to panelists informally.
Platform: We hosted our events on Zoom. This generally worked well, even for large events. However, we did hear reports that Zoom is blocked in certain countries so these participants were only able to watch recordings of events. In future years, the choice of video platforms should include consideration of at least the following dimensions: quality of audio and video; familiarity for presenters, audience, and organizers; cost; and accessibility.
Mix of events: Looking back, it is now clear that most—but not all—events were targeted to people already in the computational social science community, rather than folks hoping to join the community. If a goal of the Festival is to provide on-ramps to computational social science, then the mix of events should be reconsidered.
Time commitment: The Festival consumed a lot of time for one organizer and one TA during the second week. This limits the ability of these teaching staff to support group research projects. One way to mitigate this would be to have fewer events moderated by the organizer. Rather, they could be moderated by alumni or TAs. In addition to organizer time, many SICSS participants reported that it was difficult to attend the events while working on their group projects.
Using chat and email: As the panel was happening, the panelists would often mention papers or resources. We would then put these links into the chat so that participants could access them. We also collected up all the links shared during each event, and emailed them to registered participants afterwards.
Feedback: At the end of each event, we emailed a link to a feedback form to all participants. Response rates were low and seemed to decline over the week. Most feedback was very positive. The most common suggestions were to make the events longer or to add more time for questions from the audience.
Registration and attendance: Attendance at the events was quite good, and we had about 650 total attendees. We also found that about ⅓ of registered participants actually attended.
- Panel discussion on teaching computational social science, 240 registered, 80 attended
- Measuring cultural change in digital trace data using diversification rates, 150 registered, 60 attended
- Discussion on diversity in computational social science, 190 registered, 80 attended
- Computational social science to address the (post) COVID-19 reality, 325 registered, 80 attended
- Panel discussion on digital and computational demography, 140 registered, 60 attended
- Using Empirica for high-throughput virtual lab experiments (Session 1) 30 registered (capped), 25 attended
- Creating open source software as part of an academic career, 170 registered, 60 attended
- Panel discussion on the non-academic job market in computational social science, 250 registered, 130 attendees
- What Can the SICSS Community Do to Recognize and Eradicate Anti-Black Racism in Computational Social Science? 55 registered (restricted to SICSS current participants and alumni), 30 attendees
- Opportunities and challenges with industry collaborations 200 registered, 40 attendees
- Using Empirica for high-throughput virtual lab experiments (Session 2) 30 registered (capped), 20 attended
Post-departure
This year it feels like there is less to do post-departure. We have organized our teaching materials and the teaching materials from other locations. We have also read through the evaluation form from participants at our location and other locations. Finally, we have compiled this post-mortem, which we hope will help with next year’s SICSS.
BAY-SICSS
The Bay Area SICSS partner site (BAY-SICSS) was co-organized by Nick Camp, Jae Yeon Kim, and Jaren Haber (SICSS-Princeton 2019). The institute was held remotely from June 16th to July 3rd, 2020, and was co-hosted by Stanford University (Institute for Research in the Social Sciences, Human-Centered AI Initiative, and the School of Humanities and Sciences) and the University of California Berkeley (Berkeley Institute for Data Science and D-Lab) . Sharad Goel (Stanford) and David Harding (Berkeley) are co-faculty sponsors. BAY-SICSS had a site-thematic focus on computational social science and community engagement. Our goals for our site were to build a community of scholars and practitioners in the Bay Area, introduce participants to different forms of community-engaged work, and give participants opportunities to develop computational skills and apply them in partnership with local non-profit organizations (Code for America, DonorsChoose, HopeLab, UCSF NLP Community and PanaceaLab, UCSF Library).
In this post-mortem, we describe: 1) advertisement, outreach, and logistical planning for the institute, 2) programming for the first part of BAY-SICSS, which focused on group exercises and skill-building, 3) group projects pursued in the second part of the program, and 4) challenges and lessons learned during the institute.
1. Pre-Institute Outreach and Planning
Given our goal of establishing an enduring network of community-engaged social scientists in the SF Bay Area, we also sought to engage the CSS institutes and communities at UC Berkeley and Stanford. We secured funding from Stanford’s Institute for Research in the Social Sciences, Human-Centered AI Initiative, and School of Humanities and Sciences. We also secured physical meeting space at the Berkeley Institute for Data Science (BIDS) and administrative support from UC Berkeley’s D-Lab. In addition to such institutional support, we raised more than USD $50,000 from various institutes at Stanford and UC Berkeley and HopeLab to host and support our participants.
Like all our plans, these arrangements of support changed with the COVID-19 crisis. BAY-SICSS took place virtually instead of at BIDS, we used Zoom instead of recording sessions through the D-Lab, and the Stanford grants–which we no longer needed to accommodate in-person logistics (e.g., food and housing)–were rescinded. Nonetheless, these institutes continued to provide institutional support by consulting on logistics, forwarding emails, storing our funds (especially the D-Lab), etc. Also due to the public health situation, we delayed our application deadline from March 15 to May 1 to allow time for advertisement and applications for the virtual incarnation of BAY-SICSS.
Our process of community development and soliciting partnerships took place in three rounds. First and earliest, we recruited community partner organizations (described in detail below). Second, in December we began recruiting TAs through broad outreach (including through departments’ graduate student officers) to graduate students and postdocs at UC Berkeley and Stanford, with special attention to CSS communities. Our goal was to recruit from UC Berkeley and Stanford a total of five TAs diverse by race, gender, and disciplinary background, but sharing teaching experience, interest in community-driven research, and computational skills. We ended up with four PhD students and a postdoc–three of whom came from Stanford and two from UC Berkeley–in Education, Linguistics, Computer Science, Business, or Sociology.
Finally, in early February we began advertising BAY-SICSS to various departments and research centers at Stanford, UC Berkeley, UCSF, UC Davis, and national and international academic associations. As a result, over some months we received 129 highly qualified applications from all over the United States, Canada, UK, Germany, Norway, Finland, Turkey, Singapore, and India. Given that our format shifted to virtual, we confirmed the continued interest of the vast majority of those who had applied. Of those still interested in attending, we selected 20 participants. Our criteria for selection were as follows:
- Experience with computational applications (text-as-data, machine learning, AI, open-source software development, etc.) and/or community-driven research (governmental, clinical, policy-oriented, engaging disadvantaged communities, etc.)
- Basic proficiency (or better) in R, Python, or similar
- Rooted in the San Francisco Bay Area by geography or affiliation
- Likelihood of sustained research collaborations with Bay Area-based communities
- Diversity by race, gender, discipline, communities studied, and/or institutional affiliation
See below for the race and gender of our selected participants.
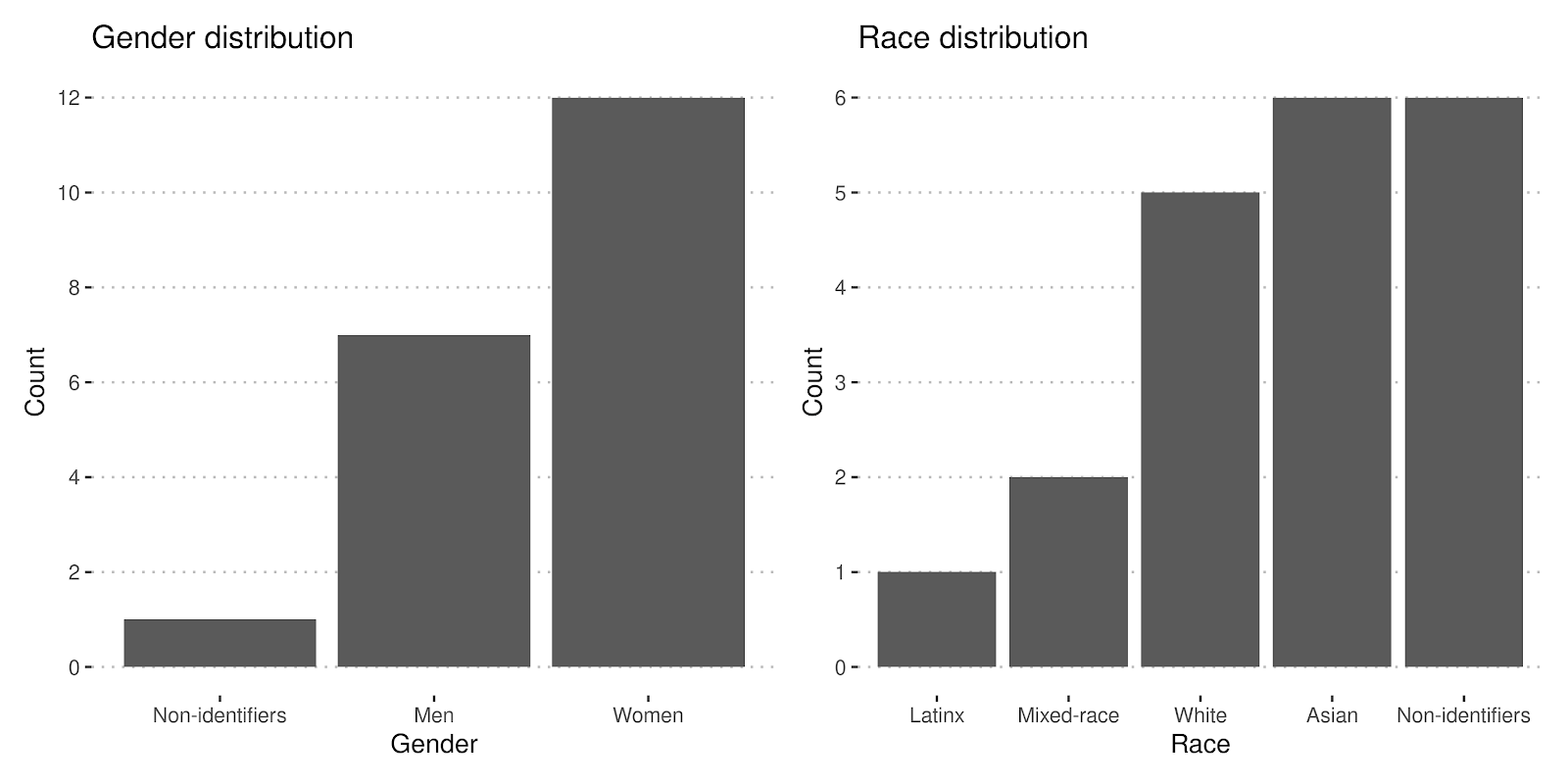
Community Partners
The foundation for BAY-SICSS is engagement with community partners applying computational social science (CSS) to study social issues and promote social good. Our greatest early support in this effort came from our first partner organization, HopeLab, whom we were made aware of shortly after SICSS 2019 at Princeton (where the organizing team came together). HopeLab had reached out to the SICSS-Princeton 2019 to discuss the potential for a partner location on the west coast of the United States. As we discovered by meeting with HopeLab leadership early in our organizing process, they shared our goal of using CSS for social good; their specific aim is supporting youth health through behavior-change technology (apps, chatbots, digital games, etc). HopeLab expressed unique interest in supporting BAY-SICSS, offering our first grant from a partner organization. These funds ultimately supported our curriculum, honoraria, and seed funding for post-BAY-SICSS participant research projects.
Immediately following SICSS 2019, we began identifying other potential partners through web search, suggestions from HopeLab, reaching out through our professional networks, and consultation with the CSS communities at UC Berkeley and Stanford. We offered partners the benefits of instructionally supported, autonomously run collaborative projects as well as the opportunity for 1-2 members of their staff to participate in Part I of the institute. It was essential, slow, time-consuming groundwork to discover, contact, and discuss with possible partners, and some late-stage possibilities fell through due to funding challenges and the COVID-19 crisis.
Our second partner to step forward was Code for America, which uses data science and technology to improve accessibility of food stamp applications and other governmental safety net services. Reaching out through Code for America’s network of social good-oriented organizations, the next partner to emerge was DonorsChoose, which uses algorithms to direct crowd funding to teacher-led projects in U.S. schools. We also made contact with the UCSF (Clinical and Biomedical) NLP Community, from which two joint collaborations emerged. First, PanaceaLab proposed an analysis of a massive COVID-19 Twitter data set. Second, the UCSF Library offered a large collection of digital documents from the HIV/AIDS epidemic, a project called No More Silence.
Our TA team played a central role in developing relationships with collaborators and early development of research projects. We paired one TA with each partner in the weeks preceding the institute, and they helped identify relevant data sets and research questions, define the scope of projects, set expectations for deliverables, and articulate what the skills our participants could bring to bear on these challenges.
A purposeful strength of BAY-SICSS was the topical and methodological diversity of our community partners. Our shared commitment to doing CSS for social good in a time of crisis brought together a range of domains: youth health (HopeLab), government services (Code for America), classroom support (DonorsChoose), and public discourse in crises past and present (No More Silence and COVID-19 Twitter). We were fortunate that our partner organizations–especially those that joined our cause early on–remained involved despite public health uncertainty and related challenges (remote workplaces, new responsibilities, etc.). Indeed, the relationships we formed with partners early on proved a critical resource, bolstering our structural resilience and supporting a creative, research-oriented response to the public health crisis that emerged late in our organizing process.
2. Part I – Skill Building
Once we made the decision to host BAY-SICSS as an online-only institute in April 2020, we faced the challenge of how best to adapt the traditional SICSS schedule to a remote format. Other post-mortems have identified the challenges of “Zoom fatigue”; we also recognized that our participants had other obligations post-COVID that they might not have had with an onsite, full-time institute. We therefore asked participants to block out half of their day, from 1pm to 6pm PST. This time was split between group projects and guest talks, with a break in-between. In addition, because coordinating group activities via Zoom is challenging, we also shrunk the targeted number of participants from 30 to 20.
We adapted the group activities from SICSS-Duke; after a brief introduction and review of the corresponding material, participants worked on these projects in breakout rooms. Our TA team was large enough such that we could embed a TA in each breakout room to assist participants, which proved to be useful. However, we had difficulties finding a way for participants to actively code together; Google Collab tended to be too slow, and screen sharing served as a bottleneck for participants who wanted hands-on experience during the activities. As a result, many participants made less progress than they would have liked in the time allotted. To address this, we gave participants time during Day 4 of the program to either work on the scheduled group activity, or to go back to one of the previous activities. This also allowed participants to hone their skills in their particular areas of interest.
We invited 19 guest speakers with expertise in computational social science in the public interest and confirmed 10 of them (53% yield rate). The gender ratio between men and women guest speakers is 9:1. The result partly stems from the fact that the decline rate was much higher for women (one out of eight) than men (nine out of eleven). These guests ranged from methodological experts (Susan Athey, Sharad Goel, Johan Ugander, Dennis Feehan, Eli Ben-Michael), to researchers working in applied settings (Johannes C. Eichstaedt, Sameer B. Srivastava, Aniket Kesari), to representatives for community-engaged scholarship (Luke Terra), to ethics experts (Rob Reich), to our community partners (all our partner representatives pitched about their organizations, data, and projects). This diversity was important given the range of participant interests and the thematic focus of BAY-SICSS. Through feedback, we learned our participants appreciated the range of speakers, and their questions ranged from the statistical to the practical. During the first week, these talks also served the purpose of introducing participants to our community partners, and preparing them for their projects during the second part of the institute.
3. Part II – Partner Projects
Our site took a unique approach to participant projects by working with partner organizations. Where some other sites made group projects optional or participant-initiated, we matched each participant with one of our community partners for projects during the second part of the institute. Since one week of full-time effort would not be practical during the COVID pandemic, we asked participants to accommodate two weeks of part-time work with their partners. BAY-SICSS convened as a group for talks in the evening of Part 2.
We were fortunate to have a range of community partners, each with different goals and expectations for the institute. Some partners offered projects open-ended in data and research questions, while others had prepared a specific research agenda and curated data set. One partner even looped employees into the projects alongside our participants. This meant that participants had choices in terms of the content area, project goals, and level of coding challenge during the second part of the institute.
Each partner supported research collaborations investigating the COVID-19 pandemic in some way, which each introduced through a presentation on Days 4 and 5 of BAY-SICSS to generate participant interest and begin relationship-building. HopeLab helped develop research into the unequal impacts of the public health crisis on youth well-being. Code for America supported analyzing changes in food stamp applications to learn what communities are most in need. DonorsChoose focused with participants on how remote instruction changed the nature and spread of requests to fund educational projects. And the NLP@UCSF and PanaceaLab team brought into focus public dialogue about the pandemic.
Participants were matched to partners on Day 5 via survey. We designed matches to ensure that each partner had enough skilled coders to accomplish its aims–especially in NLP, in some cases–but we were also able to match almost all our participants with their top choice for community partner. To honor participants’ stated interests and the possibility of multiple sub-teams, we also allowed HopeLab a slightly larger group of participants.
Unfortunately, no participants indicated primary interest in the No More Silence project, and only two named it their secondary preference–much less than the other projects. This distribution of interests left us little room to create a collaborative team with the No More Silence project, and consequently no research collaboration took shape. This was our last choice, given the project’s importance and our implicit assurance that collaboration was the premise of their involvement. We expected more interest in a project that aims to learn from previous pandemics–especially their relationships with structural inequalities by race, class, and gender.
To further facilitate the projects, we assigned each partnership a TA as an intermediary between organizers, partners, and participants. We introduced participants to their matched partner organization over email and Slack and had several check-ins during weeks 2 and 3. Otherwise, we let groups decide their own collaborative structure, including meeting format and frequency, task distribution, timeline, and deliverables.
- Lessons Learned
An eternal challenge of summer programming is covering material within the time allotted. This would have been the case regardless of circumstance, but with the adjustments for a remote institute, it was a particularly thorny issue for us, especially with regard to the partner projects. Much of the work of partnership takes place through relationship-building and observation; our participants and partners had to condense this into two half-days in a virtual setting. That said, we were happy that participants got the chance to practice not just their computational social science skills, but also their strategic thinking on behalf of our partner organizations.
Indeed, we adopted a strategy of giving our participants a sampling of different aspects of CSS for social good, while providing resources and support to follow up based on interest. We believe this approach connected our participants to approaches they might not otherwise have been exposed to. Further, many participants had expressed a desire to engage in applied social scientific work, but did not have models of how to develop and pursue those collaborations inside or outside of academia. We received positive feedback that BAY-SICSS provided several examples that participants could draw from.
Another common challenge we faced with other sites was creating community remotely, and maintaining that community throughout the institute. To this end, we:
- hosted a happy hour on the first day of the program
- held frequent breakout groups during Part I so participants could get to know each other
- had unstructured “hang-out time” in Zoom at the end of our sessions
- created a BAY-SICSS directory with our participants’ interest, and
- encouraged participants to use Slack for both essential and nonessential communication.
We feel that these measures supported open lines of communication between small groups of participants, albeit at a lower level than we would have liked. Slack was particularly useful for participants, since conversations could be held asynchronously across time zones. In retrospect, we would have encouraged participants to self-disclose more information before and early in the institute, such as through flash talks and/or sharing in Slack. However, since most of the participants are local to the Bay Area, we are optimistic that their contacts during BAY-SICSS can result in further conversations and, hopefully, in-person collaboration post-COVID.
Regarding not forming a research team with No More Silence, we think participants’ interests were driven by the pressing challenge of the COVID-19 pandemic, which plays a more clear and present role in the other projects. Another likely cause was the overlap between No More Silence and the COVID-19 Twitter project, which similarly was focused on text data, loosely structured, and led by the NLP@UCSF team. Finally, the size of the participant pool perhaps played a part, as greater numbers may increase diversity in interests and organizational flexibility in allocating participants. As such, we encourage future organizers to carefully consider socio-historical context, overlap between projects, and number of participants when planning collaboration with potential community partners.
A final lesson that bears repeating is the importance of preparation. With the other constraints of a remote SICSS, the time we spent with partners before the institute paid off during the participant-partner projects. By the time of the institute, the projects may not have been set in stone, but partners had a rough sense of the problem space, and participants had the opportunity to collaborate with them in project development. However, we received feedback from our partners that they would have liked a better sense of the Part I content before the institute (instead of being referred to the schedule). In other words, part of the task for the partners was gauging participants’ skills; that time could have been spent elsewhere. We recommend having lines of communication open and active not just between organizers and partners, but between partners and participants as well.
SICSS-Istanbul (Kadir Has University) organized by Akin Unver and Matti Nelimarkka
1. Outreach and Application Process
We have advertised this year’s SICSS-Istanbul via Linkedin, Twitter, Facebook, Kadir Has University website and through the word-of-mouth alumni network. We discovered that the positive marketing of last year’s Istanbul alumni had contributed the most to this year’s applicant pool. Outreach began in January in tandem with most other sites.
Application materials required a CV, proposal and statement of purpose. This year, we decided not to request recommendation letters because we felt that most professors end up not sending them. We believe this is because professors see this as an unwelcome chore since SICSS isn’t a graduate school. This problem leads to a lot of competent applicants ending up without recommendation letters. Plus, we have been able to gauge the quality of applicants sufficiently from their written work and CVs, and discovered that hastily-written recommendation letters don’t really contribute much to our assessment in lieu of the applicants’ own statements. This has significantly increased the efficiency of the assessment period.
We were particularly happy to see that this year’s applicant pool included a very diverse geography: North America, South America, Europe, MENA region and East Asia, including some of the top institutions from the United States and Europe. Most of those applicants decided to drop out of SICSS altogether due to COVID-related family and health issues, as well as time zone difficulties after we decided to change the format to virtual. However, this was a welcome development as we are striving to render SICSS Istanbul a truly global site, rather than merely ‘SICSS Turkey and its neighbours’.
Given the backgrounds and topic areas of applicants in 2019 and 2020, we are currently considering launching a thematic SICSS that is geared towards comparative politics and international relations scholars. These two fields are dominant in our applicant pool. We will discuss this with the main SICSS leadership and perhaps coordinate with other satellite sites next year, in case other sites are also considering thematic SICSS programs.
2. Onboarding
We followed Duke site protocols in terms of using Google Forms to coordinate ‘pre-arrival’ logistics: Slack coordination, names, bio, and photos. T-shirts were handled centrally by the Duke site; we guided applicants to the Duke link for t-shirt logistics.
The most important pre-arrival innovation we experimented with this year has been the ‘Pre-SICSS Tutorial Program’. We discovered in 2019 that the diverse backgrounds of the applicants required additional coordination and harmonisation of skill sets, research questions and short-term trajectories. To that end, this year we introduced a two-week ‘Pre-SICSS’ training module to refresh participants’ programming skill basics, theoretical understandings of computational science and get to know each other better. Our Pre-SICSS program was designed as an HTML document to refresh R skills, prepare participants for web scraping, requesting tokens, the structure of online surveys and basic methods before they take on the ‘real’ SICSS. We designed this document in meticulous detail this year so that we can re-use it next year with minimal revisions and changes, so that this pre-SICSS period becomes as sustainable as possible from a workload point of view; both for the organizers and the TAs.
This was a resounding success. Not only that the applicants were already fully coordinated at the time of the first day of SICSS, but we had already resolved some of the logistical and technical problems way ahead of the program so that our real-time interaction with SICSS-Duke continued without any impediments. Participants were unanimously happy with pre-SICSS and expressed that this prep period significantly increased their overall benefit from the actual SICSS, as well as their preparations for group projects.
Next year, we will retain pre-SICSS as a two-week virtual/online prep period, so that when people come together in person for the real SICSS, they are already up-to-speed with technical foundations, readings, theoretical training and with each others’ work. One idea is to introduce daily reading discussion sessions to the pre-SICSS training phase. Because participants have indicated that pre-SICSS did very well in bringing the technical skills up to speed, but they required far more reading and contextualizing articles, as well as more frequent discussions of them.
During the pre-SICSS prep period, we held a Zoom session every three days for Q&A as ‘Zoom coffee/lunch’ sessions. Organisers and TAs were also on-call on Slack to answer any specific questions. This model worked well during the actual SICSS too and much of research coordination was conducted this way on Zoom.
3. Week 1
Following the two-weeks of pre-SICSS module, participants were slightly tired, but still very energetic and driven to take the real program head-on. Participants were required to watch pre-recorded lectures before that day’s session. Sessions began at 4pm Istanbul time to accommodate participants from Argentina, Canada and the United States. Beginning with Day-1, participants were already prepared in using break-out rooms on Zoom, roamed across other breakout sessions to socialize and quickly form research groups to solve that day’s tutorial problems.
Flipped Classroom Model and Applied Scenarios
This model worked well and we are considering using it next year as well. We are considering getting participants to watch pre-recorded SICSS videos as a required task so that the first week could be dedicated to applied tasks. Two years in a row, the participants conveyed their belief that more skill-building and practical tasks or scenarios are required rather than lengthy lectures. We believe these comments have a point, as specific technical tasks based on particular scenarios make more sense as integrated workflows instead of isolated exercises. Scenarios also work better in terms of bringing people together as coherent groups and prevent individuals or small groups from self-isolating.
Curriculum
Two years in a row we received significant demand to introduce geospatial analysis and social media mapping tools into the program. For next year, we are considering preparing a lecture and a skill-building scenario so that the participants can work more on the spatial dynamics of digital data. Although this year we introduced agent-based modeling into the SICSS through an external speaker, the case study she introduced wasn’t built on computational data so it didn’t fit well with our purposes. Next year, we’ll try to find more computational ABM researchers to walk the participants through the details of this method. Finally, participants have requested discussing Ethics later in the curriculum. Ethics discussions without coming face to face with ethical dilemmas in practice becomes too abstract and participants believe that covering Ethics the last will make more sense and build greater awareness on the issues involved.
4. Week 2
Alumni talks
We asked well-performing SICSS groups from last year to present their ongoing work this year. This worked well, as we were able to build additional synergy between the classes of 2019 and 2020 and some of them are now discussing building new research clusters for overlapping research questions. This was also good for the morale of the 2020 class as they were able to see how research projects start small and build up incrementally, as many disheartened groups felt much better about their group projects after these alumni talks. We’ll retain these presentations next year as well.
Group Projects
Groups have worked together by using collaboration platforms like GitHub, Google Documents, Google Colab. Slack etc. TA separate Slack channels for them. In their channel, they are asked to report their daily improvements. Participants were asked to prepare a proposal including a research question, theoretical/conceptual framework, data, methodology and expected outcome in the beginning of the second week. During the project week, participants frequently consult with our organizers, TAs and guest speakers to develop their projects. Before the presentations, they are asked to prepare a brief description of their projects and a GitHub page to put everything in it. Both descriptions and relevant links were put on the SICSS Istanbul schedule page.
5. Opportunities and challenges of an online SICSS
-
Managing timezones and schedules were still tricky this year. Much of this trickiness came from the fact that 75% of our participants attended from a diverse range of timezones. Still, we were able to accommodate them, but of course when will hopefully do this again next year physically, this will be less of a problem
-
Zoom ‘coffee hours’ were necessary, but we felt that a lack of naturally-occurring socialization also kept shy people from reaching out on Slack or Zoom to ask questions.
-
We introduced breakout coffee chat rooms to improve this a bit; this had limited success. People were most engaged in smaller groups but still easily bored due to the online nature of forced-socialization.
-
Communication and reminders have to be more meticulous as participants had some difficulty following reminders during the first week.
6. Community Building
To keep the SICSS-Istanbul community connected, we may organize a small zoom session(40 mins) for each month. Potential topics would be discussing alumni’s research projects, having short tutorial sessions for programming (we can ask from experienced alumni to run these sessions), hosting guest speakers or just chatting. Thus, alumni would have a chance to improve their research ideas, programming skills and collaborations. I propose this because our participants have a lack of possibilities to come together like other sites at International Conferences etc.
SICSS-Maastricht organized by Monika Leszczynska and Catalina Goanta
Teaching assistants: Thales Bertaglia, Bogdan Covrig
1. Outreach and application process
Timeline:
- mid-February: we started the first promotional activities.
- March 10: we paused promotional activities due to COVID-19 and many events being cancelled at that time.
- March 25th: our initial deadline. We received only a handful of applications in that round.
- April 9th: we decided to hold a virtual SICSS-Maastricht, reopened the application procedure and resumed promotional activities.
- May 5th: new deadline.
- May 13th: we sent out approval emails to 20 candidates.
Numbers:
- 35 applications (first and second round).
- 20 invited participants
- 19 participants accepted our invitation. One participant rejected because she was admitted to SICSS-Rutgers.
- 15 participants actively participated in SICSS-Maastricht. 4 participants dropped out for various reasons.
- 10 participants participated in Week 2 research projects.
Additional info:
- We used various channels to promote SICSS-Maastricht – Facebook groups, mailing lists, Twitter, emails to researchers from our network. When reaching out to people in our network we selected those who may have contact with legal scholars potentially interested in computational social science methods.
- We asked all applicants who applied within the first deadline if they are interested in being considered for the virtual SICSS-Maastricht. We received mostly affirmative responses.
- We set up a gmail account for SICSS-Maastricht and asked applicants to send one combined .pdf with all application materials directly to this email address. This mostly worked well, but there were a couple of participants who, nevertheless, submitted all documents in separate files. This resulted in a bit more effort related to downloading and sorting files, but was still manageable.
- We did not ask for recommendation letters. We had an impression that the application materials that we asked for (CV, statement of interest, writing sample) were sufficient to decide whether to accept a candidate. We found statements of interest particularly helpful.
Things to improve and some afterthoughts:
-
We think that putting even more attention to the statements of interest might have been a better strategy during the selection procedure. We had an impression that enthusiastic and engaged participants are the key to the success of the Institute. We believe that it is something that can be inferred from the statement. This might be again something particular about our location, since we received some applications from people with little or no experience in social science methods in general, so enthusiasm and engagement were really crucial in those cases.
-
We could have provided more information about the schedule of SICSS before the application deadline. We received a couple of emails from people asking about the details of the schedule since they were not sure how such a virtual event would look like. Providing more information in advance would save us some time spent on replying individually to these emails.
2. Pre-arrival and onboarding
Email communication: We sent only two emails to accepted participants – with the acceptance decision and with an on-boarding message.
Content of the on-boarding message:
-
We asked participants to send their short bios and pictures (this was sent via email and later uploaded to the website). Most of the participants emailed their pictures and bios within the deadline. We had to follow up on a few of them on Slack.
-
We asked participants to record a short talk presenting their ideas for a project that they would like to work on during Week 2. 13 participants sent their flash talks.
-
We also referred participants to our website with pre-arrival materials. We explained that we will be using Slack for further communication. We also provided them with a tentative schedule.
-
We informed participants that if they do not want to work on group projects in Week 2 or did not manage to form a group, they will have an option to participate in SICSS-Festival activities.
-
Slack communication: We immediately added all participants to Slack and continued to communicate with them solely via Slack. Slack did not seem to be a problem for any of the participants. We quickly started communicating with them there and it worked well. Some participants had to be reminded to join us on Slack.
-
Things to improve and some afterthoughts: One thing we noticed at SICSS-Maastricht is that we had quite a few participants with little or no coding experience. The pre-arrival materials were not sufficient for them to be able to fully participate in Week 1 activities. It might be something very particular to our location, since we did have a few participants with purely legal education. We thought about two ways to improve it when it comes to on-boarding:
-
Offering participants with no coding experience to arrive one or two days earlier (if SICSS-Maastricht takes place in the future and in person) and having 1-2 days of an intensive coding course in R.
-
Adding more pre-arrival materials such as Dataquest.
Week 1
General Info:
-
Most of the activities took place from 12.00 CET to 19.00 CET. Most participants were from the European time zone, but we also had people joining from GMT+3 and GMT+4.30. One of the organizers was in GMT-4 time zone.
-
We started SICSS-Maastricht on Sunday at 17.00 CET with meet and greet following this model. Most of the participants as well as one of the guest speakers joined us on this day. After two rounds in breakout rooms of 3 people, we created breakout rooms based on the topics suggested by participants and we stayed there for about 30 minutes. In the end, some people left and other participants joined one breakout room and continued conversation for some time. The whole meeting lasted about 2 hours. The format and the meeting seemed to work really well for people to get to know each other a bit.
-
We had 6 days of training – 5 days in Week 1 and 1 day in Week 2. We mostly followed the topics of the main SICSS-Duke and relied on video lectures recorded by Matt and Chris except for Day 5.
__Recurring activities:
-
Almost each day, we had lunchtime sessions from 13.00 -14.00. During the first four days we discussed flash talks, afterwards we switched to topics suggested by participants or by organizers. During the first four days, we assigned 3-4 flash talks per day that participants were asked to watch before our online session. Flash talks were uploaded on YouTube, a playlist for each day was created. During lunchtime meetings, we used breakout rooms to discuss the flash talks – one break out room for each flash talk. Presenters were asked to stay in their breakout rooms, others were encouraged to move around to the breakout rooms where a flash talk of interest to them was discussed. We received very positive feedback from participants regarding lunchtime sessions. They seemed to enjoy them a lot.
-
Each day we had an invited talk that participants seemed to like a lot. These talks were open to everyone who registered. We promoted invited talks on Twitter and within our Maastricht Law&Tech Lab. We usually had, in total, about 25-30 people joining.
Special activities on each day:
-
Day 1 started with a short introduction, in which we explained how CSS can be applied to law, the structure and logistics of SICSS and repeated some of general principles introduced by Chris Bail in his introductory talk. We continued with a lunch session, an invited talk on research ethics with legal data by Argyri Panezi, group exercise discussing the research ethics case study that followed the lesson plan as at SICSS-Duke (breakout rooms – 3 persons in a group + whole group discussion for 30 minutes) and finally a keynote talk by Johan Bollen.
-
During day 2-4 we had the following schedule: We started with an invited talk (60 minutes) and participants seemed to like that a lot. We continued with a lunchtime session (60 minutes). Afterwards, we had group activities (3 hours). In the evening we had a one hour debriefing during which we discussed the group activities. Each group presented what they did and reflected upon the activity. This worked very well.
-
Day 5 covered Network analysis in Law. We started with a general lecture by Gijs van Dijck on network analysis (60 minutes), followed by a lunchtime session. In the afternoon, we had a workshop on Gephi by Gijs van Dijck and Constanta Rosca. During the workshop participants could practice the concepts they learned in the previous lecture and see how they can use Gephi for network analysis (90 minutes). At the end of the day, we had 2 hours scheduled for a group activity. However, participants seemed to be already really tired on that day and we finished early.
Additional info:
-
With some exceptions, we followed group activities suggested by Matt Salganik and Chris Bail. Group activities were scheduled for 3 hours, during which participants could take a break, but it was up to them when. Participants were assigned to groups of 4, max 5. We took care to distribute to different groups participants with knowledge of a method practiced on a given day. Others were assigned randomly. Teaching assistants were all the time going from one breakout room to another to help participants with their group activities. This seemed to work very well.
-
Day 4 activity was adjusted to the fact that we had mostly participants with a legal background and from Europe. We used Prolific instead of mTurk. We created temporary Gmail accounts and temporary Prolific accounts using these emails. Prolific accounts were topped up with money. This worked without any issues. Participants found the task a bit too ambitious, but they seemed to enjoy the group activity on that day. Each group reporting back the results of their task was stressing how much fun they had and how well they worked with other group members.
-
Each day our team (organizers and TAs) had a debriefing during which we discussed what went well and what went wrong on a given day and talked about the next day’s activities.
Things to improve and some afterthoughts:
-
We received very positive feedback after the first day. However, it was also a tiring day for participants. In particular, participants needed to move a lot between different Zoom meetings (see Logistics section). Based on participants’ feedback after the first day we built in an additional break in the early afternoon. Participants also mentioned that it may be worthwhile to remind that it is possible to move between breakout rooms during the lunchtime sessions. Therefore, we encouraged that on the next day. Finally, some participants mentioned that it is difficult for them to discuss research ethics issues if they had not yet had any experience working with data.
-
After Day 2, some participants complained that 3 hours is too long for a group activity. On Day 3, we explicitly mentioned again that they should take breaks at their convenience. This seemed to help.
-
We had some issues in coordinating how to code together. Usually, one person shared her screen and coded. It was usually the most experienced person in the group who also explained the code. Others were encouraged to try to code themselves on their computers. This did not always work well. In particular, participants with no or little coding experience seemed a bit lost. We thought that for the future, we could organize one-on-one office hours at the end of the day, during which participants could go through the code that was written on that day together with teaching assistants who would explain it step by step.
-
Scheduling of flash talks could have been improved. We did it on the first come first served basis, i.e., flash talks were assigned to each day in a sequence in which they were submitted to us. Some participants had other commitments on some days and they missed lunch time sessions during which their flash talk was supposed to be discussed. We tried to re-schedule, but in the end two flash talks were not discussed.
-
We may in the future encourage our guest speakers to focus even more on methods they used in their own research.
-
Overall, we think we manage to create an informal and relaxed atmosphere over Zoom. We played some music at the beginning of each session when participants were joining the meeting. We used Snapchat filters. After the first day, we also reminded participants to always notify us about any technical issues. We reacted immediately if someone had connectivity problems by, for instance, switching off cameras. We have an impression that participants felt very comfortable speaking up and that the virtual setting was not intimidating for them.
-
Day 5 (Network Analysis in Law) group activity could have been improved. It is difficult to pin down the reasons for why the group activity did not work well. It may be that participants were simply exhausted after the whole week. It may be also that it was challenging for them to figure out how to use network analysis for legal questions. We may improve this group activity in the future by, for instance, giving more specific tasks to practice Gephi and suggesting specific questions that participants could try to address during the group activity.
Week 2
Schedule:
-
On Monday, we had the last training day (Experiments in the Digital Age). We started with an invited talk, followed by a lunchtime session. Afterwards, we had a workshop (90 minutes) on Introduction to oTree by Philipp Chapkovski.
-
At the end of the day, we had 60 minutes to finalize group formation for Week 2 group research projects. We started by asking participants to write in a Google spreadsheet their ideas for research projects that were generated during Week 1 by describing the topic and members of the group. Other participants could enter their name next to the project they found interesting. We created three breakout rooms based on these ideas and participants could move around to talk more about these topics. Next, we did twice a random assignment to breakout rooms of 2 people and asked them to generate further ideas and add them to our existing topics. Based on the topics entered we created 7 breakout rooms that participants could use to continue their discussions on the topics they have generated. We left the rooms open and participants stayed there for another 45 minutes. Two groups – one of 7 people, one of 3 people were formed and presented their projects on Friday.
-
Groups were asked to send their proposals by Tuesday 16.00. They were offered small grants to work on projects. None of the groups requested any funding.
-
On Tuesday and Thursday we had only a lunchtime session and office hours in the late afternoon.
-
On Friday, we had 2 group projects presentations, one hour each.
Things to improve and some afterthoughts:
-
In general, the biggest challenge for participants was to accommodate their daily commitments and SICSS activities. A few of them missed some of the activities. Many could not join Week 2 projects due to other tasks they had to work on.
-
Only a few participants joined the lunchtime sessions in Week 2. We thought that maybe we should provide a more specific topic for a lunchtime session, since participants already run out of ideas for these sessions. This could have encouraged participation. On the other hand, they seemed to work a lot on their research projects, so we also did not want to overburden them with many additional meetings.
-
The oTree workshop seemed to work well, but part of it was found too technical by some participants. For the future, we may want to add another 90 minutes and ask participants to install oTree on their computers. One idea would be to provide them with a code for a simple experiment and ask them to adjust 2-3 features, based on detailed instructions. This would allow them to read the code, get to know the structure of oTree better and try it out themselves without requiring too much technical knowledge.
3. Logistics
-
Zoom: We used two Zoom links – one for internal meetings, one for meetings that were opened to non-SICSS participants. This seemed to work pretty well. We did not have any big issues – there were some connectivity issues, but we managed to handle them by switching off cameras etc. On one day, we had some issues with interrupted meetings. We still could not figure out why. We also always had a waiting room from which participants were let in into the main room. This seemed to work well. No one complained about this.
-
Slack: On Slack, we first had two channels – #maastricht and #maastricht-invited-talks. The second one was designed to allow participants to communicate with guest speakers. This did not seem to work very well. Some of the speakers were very enthusiastic about SICSS-Maastricht. We could have invited them for lunchtime sessions and allow participants to interact with speakers in a more informal atmosphere. This would have been better than a Slack channel.
-
In the middle of Week 1, we created a separate channel only for announcements since our main channel got clogged with announcements and resources shared by us and participants.
-
Participants also suggested creating a separate repository for all the code they create and data they collected during this week. We still need to do that.
SICSS-Montreal organized by Vissého Adjiwanou (SICSS-Cape Town 18, 19, SICSS-Princeton 17) and Julie Hussin
From June 15 to June 26, the first edition of the Summer Institute in Computational Social Science (SICSS) is held at the University du Québec à Montréal (UQAM). Previously planned as on-site event, it finally moved online due to the Covid-19. The SICSS-Montréal is organized by Dr Vissého Adjiwanou, associate professor of computational and quantitative methods at the Université du Québec à Montréal (UQAM), and an adjunct professor at the Département de Démographie at the Université de Montréal. Dr Adjiwanou is also the chair of the Scientific Panel on Computational Social Science at the Union for African Population Studies (UAPS). The summer institute is organised in collaboration with Duke University and supported by the Russell Sage Foundation, the Alfred P. Sloan Foundation, and the Institute for Data Valorization (IVADO). About 40 applications were received for the summer institute and 19 were participants accepted, from both English and French-speaking languages. Ten participants are from Montréal and Toronto areas while the rest of the participants are from Africa (4), America (2), Europe (2) and Asia (1).
1. Process
Because the whole summer institute is run online, the materials to the participants have been adapted to fill this form of learning. Asynchronous videos were posted to the participants before the beginning of the summer school that they were able to listen to. These materials include topics on ethics, surveys and experiments in the digital age, by Matthew Salganik, and on digital trace data collection and analysis (text analysis, topic modelling and network analysis) by Chris Bail. Those materials were of high-quality training videos that have been proven to be well understood by the participants. In addition to the videos, a synchronous course was delivered by Will Hamilton, Assistant Professor in the School of Computer Science at McGill University, on machine learning. At the opening, Vissého Adjiwanou presented the importance of the Summer Institute for social researchers and how that opens a new avenue of research to them. This first week also saw various talks by experts on the field: Stephane Helleringer (John Hopkins University) presents his works on using machine learning to predict age in sub-Saharan Africa, and William Hamilton speaks about his research on the application of machine learning in social research. The participants were also able to listen to additional presentations from the other sites.
In the second week, the participants worked in two small groups on various applied projects, that were presented on the last day. The first group developed a project to analyse whether or not the Twitter sentiments correlate with traditional survey methods that measure public approval of governmental action related to Covid-19. The participants of the group used sentiment analysis on twitter data to map it with official surveys on the economic. The second group used text mining methods to analysis ethics and social considerations about Coronavirus in scientific research. The members of this group collect scientific publications on Covid19 related to ethics and social consideration. This year group projects have been mainly an application of the methods learnt during the first week than research that will be pursued in the future. More interestingly, many have developed new research abilities and have shown enthusiasm to pursue their collaboration in the future.
2. Successes
Although it seemed unthinkable at first to run the summer institute, we were able to run a successful summer institute in Montreal. During the first week, all but two of the participants attended very well and the group exercises went very well. All participants listened to the online courses before the summer institute and the discussion was very informative. We invited an expert in ethics, Lonzozou Kpanake, during the group exercise on ethics, to participate in the discussion. This turned out to be a very interesting experience for the participants who compared their learning to the field experience of health psychology brought by the expert. In the future, it can be very interesting to get researchers who are not doing computational social science research to bring their point of view to the participants during group exercises.
3. Challenges
Running online summer institute has its own challenges as well. Those are at many levels. from the participants, it is the time lag between their place of residence and Montréal. Although many have been diligent to be present throughout the two weeks, we have unfortunately lost some participants. Some were present but very tired to fully concentrate on the group exercises. And some were lost due to their internet connexion. In the second week, we have lost many more participants and ended up with only half of the initial participants. Many of them have probably anticipated a more tedious online group project development. In another level, the simple idea of running a summer institute of this level online is just difficult, both for the participants and the organizers. At the organisation, we have to make sure that people participate in their groups and provide impactful comments to them and be present to respond to other queries from other participants. Again, remaining before the screen for long hours for the two weeks has proven to be also challenging. There were many micro-management that are not related to the courses.
Here are some pictures from the event.

Group project presentation – group 1
Group project presentation – group 2
Closure
SICSS-Rutgers, organized by Katherine McCabe, Kira Sanbonmatsu, and Hana Shepherd. Teaching Assistant: Kathleen Rogers
SICSS-Rutgers 2020 was held virtually from June 15-26, 2020 with 40 participants. Our first week focused on computational social science and small group activities, and the second week focused on launching collaborative group projects. We’ve divided this post-mortem into five main sections: 1) outreach and application process; 2) pre-arrival and onboarding; 3) first week; 4) second week; and 5) reflections on the virtual format.
1. Outreach and Application Process
Our initial plans for the SICSS-Rutgers institute were to hold the institute in-person in New Brunswick, NJ with about 15-20 participants, prioritizing participants from Rutgers and nearby institutions to build a regional community of computational social science researchers. The intended limit on participants was due to a combination of the size of the room in the Rutgers New Brunswick Alexander Library we intended to use, as well as budget constraints (with the goal being able to provide adequate meals and funding for activities for all participants).
Given this was the first time we were hosting a SICSS at Rutgers, we also planned to cast a wide net in terms of career-level, expertise, and disciplinary background to encourage more applications. However, given the organizers were rooted in political science and sociology, we anticipated recruitment would be higher in those areas, and this ended up being the case. In the future, we should be better positioned to expand recruitment to other disciplines (if desired) by connecting with participants and speakers that participated this year.
To recruit participants, in early 2020, we sent an email advertising the institute to the Rutgers University departments in political science, sociology, and the School of Communication and Information. We also reached out to the computer science department and Rutgers DIMACS to engage possible speakers and participants on the computer science/data science side of computational social science. Outside of Rutgers, we reached out to graduate program directors at many nearby universities, we advertised on Twitter, and one organizer gave a presentation at Rutgers-Newark to recruit participants. Based on feedback from participants, each of these channels appeared to be successful at least to some degree. We also had participants who learned about the institute from the main SICSS and Russell Sage Foundation communications.
Our application was active prior to the major onset of COVID cases in the United States, and the original application deadline was the end of March. We used a google form for applications. This worked well, as we were able to create a google drive folder where we could store applicant information linked to application files they uploaded. We asked respondents for their name, career stage, institution and discipline, a CV, writing sample, and a research statement. When the application initially launched, we also asked for a letter of recommendation for graduate student applicants. However, after discussions with colleagues, we removed this requirement, as colleagues expressed concerns that this could discourage underrepresented applicants from applying. We would feel comfortable moving forward without having this requirement in the future.
One additional recommendation for the future would be to frame the description of the research statement as more of an extended cover letter or narrative. We had great variation in the ways that applicants went about drafting the research statements, and some statements lacked some of the basic information that would help us learn about the applicants because the statement was strictly about a research topic. By framing the statement as more of a cover letter or narrative, it might help applicants draft their materials in ways that address all application criteria, including specific references to how they may benefit from the institute and how their research might help expand computational social science to new communities and research areas.
We also received the most clarifying questions about what the writing sample should include. This suggested that some potential applicants might find this requirement particularly daunting. To make sure this requirement does not dissuade applicants from underrepresented areas of computational social science, we might suggest adding more guidance on this in the future, such as explicitly stating this can be something other than a formal working/published paper, such as a course seminar paper or prospectus; and does not have to use computational tools.
Adjustment to Virtual Setting
Our recruitment was interrupted / stalled by the uncertainty created by COVID. We did not advertise the institute in the days leading up to our original application deadline because we had great uncertainty about whether we would be able to continue to hold the institute. Likely as a result of this lack of advertising in late March and associated uncertainty, we had very few applications come in during March. We continually updated the application deadline– moving it back until we had more clarity on how the institute would be held. We also wanted to make sure our deadline was after notifications for SICSS-Duke were released so that applicants who applied there would also have the opportunity to apply to SICSS-Rutgers. Once we knew the institute could be held virtually, we renewed our public advertising as a virtual institute. We ended up with about 47 applications to the institute by the beginning of May.
We also saw the shift to the virtual format as an opportunity to rethink the composition of participants. We recognized that a virtual institute could pose challenges for some of the benefits unique to in-person settings, such as informal community-building. Therefore, instead of trying to fully reproduce our in-person vision, we decided to shift to a vision that focused on inclusivity of background and expertise. Instead of limiting the participant pool as planned, we expanded our numbers to include any applicants that appeared to have a complete application, an understanding of the goals of SICSS, and an understanding of what would be involved during the two weeks. With these renewed criteria, we ended up with 40 confirmed participants in our SICSS event.
Our application call specifically mentioned welcoming applicants of all disciplinary backgrounds and levels of expertise, as well as a desire to include participants working on research focused on social progress, such as areas related to race, gender, sexuality, and social or economic inequality. This may have helped us expand recruitment into new communities. About two-thirds of our participants self-identified as female, and our participants were also diverse in terms of racial/ethnic background.
Overall, about three-fourths of our participants were doctoral students. About 10% were assistant professors, and others included postdoctoral scholars and lecturers. About 22% of participants were in sociology, 32% in political science, and the other half of participants included those in communication and information science, psychology, social work, public administration, and computer science, among other disciplines. Participants also had a range of prior coding/computational experience. By expanding our participant pool, we were able to accept a larger number of applicants outside of the regional area and applicants with more limited experience with computational methods. About only half of our participants were affiliated with Rutgers-New Brunswick or Rutgers-Newark, while others were affiliated with universities across the United States and in other countries. About 33% of participants were “brand new” or “not very familiar” with R. About three-fourths of participants were “brand new” or “not very familiar” with web scraping, quantitative text analysis, machine learning and/or working with APIs.
Overall, we were happy with the decision to expand our number of participants. At 40 participants, we felt the size was still small enough that every person could participate, while also allowing more opportunities for participants to meet people outside of their own discipline and institution. Most of the logistical preparation also easily scaled up. We would have had to create the same google forms and daily slides whether we had 10 or 40 participants. Overall, our participants said they would recommend that people attend SICSS in the future. That said, we would caution that full group sessions become more intimidating and less interactive with larger sizes, so we would only recommend expanding the size if a site planned on having mostly small group sessions or implemented additional ways to help make people feel comfortable participating in the larger setting. We might also recommend scaling up the number of TAs available in proportion to the expanded participants, especially if pre-arrival sessions are expanded, as discussed below.
2. Pre-arrival and onboarding
After participants were accepted, we sent each participant an email asking them to confirm their participation and send a photo and bio to be included on the website. We also sent participants links to the pre-arrival materials and Slack workspace and alerted them to the availability of office hours from SICSS-Duke TAs. Our SICSS-Rutgers TA provided office hours during the week prior to the start of the institute. Our email also stressed the importance of reviewing the pre-recorded lectures once they were posted because the institute would be a flipped classroom format.
Just prior to the start of the institute, we asked participants to fill out an informational survey regarding their experience with the SICSS topics and coding experience, as well as keywords related to their interests, which we used to help form small groups during the institute. The forms were created using google forms and sheets, and we had a high response rate. By the start of the institute, all but one participant had replied with a bio/photo and filled out an informational form.
We generally had very positive feedback regarding the pre-recorded material and pre-arrival materials provided by SICSS-Duke. However, few participants attended pre-arrival office hours. Based on feedback, in the future, we would consider adding a few live, guided tutorials through the pre-arrival R coding primers in the weeks prior to the institute. We believe a small number of participants did not fully realize the importance of the coding primers, while others felt overwhelmed by the primers when going through them alone and/or did not feel comfortable or did not know how to go about seeking help in office hours. While we do not think extending the institute — given its intensity — would be ideal, a few optional ad-hoc guided tutorials may be helpful. R has a difficult learning curve, and more actively guiding people through the early part of this curve could be very valuable. In addition to actual coding, we had many participants who were using github and RMarkdown files for the first time. Basic instructions on how to download files from github, load and knit files in RMarkdown could also be helpful. This proved especially important for the survey weighting activity, which relies on participants using an .Rmd file.
We also think stressing that people should actively “code along with” the videos in the lecture pre-recorded material is important. Many people encountered issues with the version of their R or the packages required for specific SICSS topics, particularly with rtweet and text analysis, and these issues could potentially have been resolved in the pre-arrival time period if we had all participants actively work through each of the annotated code files prior to the start of the institute. Instead, many people encountered them for the first time during the group activities, which slowed down their progress. While participants generally reviewed the pre-recorded materials, fewer were able to go through them at that added level of detail. This is likely in large part due to the timing of our application process for this year, which could easily be changed in the future. Participants generally confirmed their participation in late May, with videos also released around that time, allowing an unusually shorter pre-arrival period than in past years. The more extended pre-arrival time could allow participants more opportunities to work through the materials with the guidance of organizers and TAs before the institute starts.
The pre-arrival/pre-recorded annotated code files could also be potentially expanded to include 1-2 more exercises on web scraping, working with APIs, and applications– areas with which participants generally came in with the least familiarity. We developed additional tutorial materials for these areas that participants could use as a resource during the institute. However, having these in advance of the institute in the future may help.
Lastly, we also recommend (with a longer pre-arrival period), including some type of accountability/feedback system to make sure each participant is sufficiently encouraged to work through the material. This could be as simple as asking people to check off a form once they have made it through a video or annotated code file or a “buddy system” where pairs of participants work together in the lead up to the institute.
3. Week 1
Schedule and Activities
In the first week, each day was focused on a specific topic. The first three days, we followed the SICSS-Duke schedule. The first day was focused on ethics, the second on APIs/web scraping, and the third on text as data. Because we have several faculty at Rutgers who work on network analysis, we adjusted our schedule to include a network analysis day on Friday. As a result, we made Thursday a day that combined machine learning and surveys as topics. The morning of Monday, the sixth day, focused on experimental design. Our daily materials are available here.
The first day we began with a welcome session with the full group and had informal small breakout sessions for participants to get to know each other. In the afternoon, participants broke into small groups again to discuss a case study about ethics. We then concluded the day with a full-group session discussing learnings from the case study. From feedback on this first day, moving forward we added additional breaks into the schedule and shortened the end-of-day full group session. We found that participants had the greatest sense of “Zoom fatigue” during full group sessions and end-of-day activities. We also changed what was initially planned as “informal small group time” over lunch each day into additional, optional informal time spent with those whom participants were working with for the small group activities. We found that some groups used this as an additional break, while others used this as “working lunch” time.
For the rest of the first week, we began the day with a short discussion of the takeaways from the previous day, an overview of the day’s schedule, and a short introduction to the topic for the day. We also included an ice breaker each day to help build community, which encouraged people to make posts on Slack. We then had a mix of small-group time for working on the daily activity, a guest speaker, and a short debrief (15-30 minutes maximum) on the day’s activities. Monday, the sixth day of the institute, followed a similar format during the morning, with a short activity focused on experimental designs. On Thursday and Friday of the first week, we also incorporated live tutorial sessions during the morning. On Thursday, an organizer gave a live tutorial on machine learning. On Friday, we had a guest speaker give a live tutorial on network analysis.
Overall, participants liked the mix in formats, shifting between a large amount of small-group time (which they generally liked the most), but also breaking it up with some live full-group sessions and/or guest speakers.
Guest Speakers
We had four guest speakers the first week: Daniel Hopkins (Political Science), Thomas Davidson (Sociology), Michael Kenwick (Political Science), and Katya Ognyanova (Communication), and the second week also had four speakers: Yanna Krupnikov (Political Science), Simone Zhang (Sociology), Adam Thal (Political Science), as well as Arvind Narayanan (Computer Science) who held an informal lunch discussion and Q&A.
Participants particularly appreciated more interactive sessions with speakers where they could ask questions about the methods and tools underlying the work and for advice about carrying out work in the future. We had participants ask questions in the Zoom chat or raise their “virtual hands.” We did find that participants were more likely to turn their cameras off during guest speaker sessions, which could suggest that participants also used these sessions as an additional “break.”
We had hoped to have an even greater number and diversity of the background speakers, but had to change course in part due to the uncertainty created by the pandemic which paused our speaker recruitment and transition to a flipped classroom, shorter virtual format, which reduced the number of speakers we wanted to invite. We should also note that not all speakers responded to or accepted invitations, which was particularly common for speakers outside of academia or in disciplines outside of those connected to the organizers. We also had to cancel a special session on AI, in collaboration with a Rutgers institute, due to the pandemic. In general, recruiting speakers from a wide range of backgrounds outside of the organizers’ networks proved (unsurprisingly) hard and will likely again require substantial time in the planning stage in the future.
In addition to the planned guest speakers, we encouraged our participants to attend talks during the SICSS Festival. In particular, we incorporated the SICSS Festival talks on anti-racism and building a more inclusive SICSS community into our schedule and made sure these events did not conflict with other events at our partner site.
Logistics
We used Zoom for our virtual institute. Outside of minor individual connectivity issues, the platform worked very well. For small-group activities, we used the breakout room feature, breaking our participants into rooms with 4-6 people. Our TA developed groupings in advance of the institute based on participants’ self-reported expertise and research interests. We would recommend keeping small groups small, leaning closer to 4 participants per group, to make sure everyone can participate equally. We also advised groups to designate a specific person to take notes and report back to the full-group session, and we encouraged new people to take on this role across days. This helped empower people to participate in the full-group setting.
We have a mixed sense of whether matching people with particularly high and low expertise in groups vs. matching people with similar skill levels is better. We had some cases with mixed expertise groups where participants were able to share their expertise with others, which was a great benefit to all. However, in other cases with mixed expertise groups, those with great expertise felt somewhat frustrated initially, and those with less expertise might have felt like they could not contribute as much. Ultimately, we think keeping a balance here might be the best way to go– with some activities focused on mixing expertise, and other days focused on matching levels of expertise.
To provide supplemental support for participants, during small group activities, one organizer or TA remained in the “main room,” and we had participants drop into the main room for individual questions and troubleshooting. We also communicated with groups via Slack as they had issues or had an organizer or TA drop into a breakout room to provide support.
Overall, the breakout rooms worked really well for allowing participants to get to know each other and work together. This was probably the single best feature of the virtual format. That said, there were two primary weaknesses with a “virtual” small-group format relative to an in-person small-group format. First, it was harder for participants to collaboratively code together virtually. Participants often shared their screens to help with this, but it was still a harder coordination problem compared to a situation where someone could “look over a shoulder” to see what their group mates were doing. We also similarly found it harder to help people troubleshoot their code virtually. In general, it is harder to verbally direct people to take certain actions on their computers than to physically guide them in-person. A second weakness of the virtual format was the ability to actively monitor small groups in a non-invasive way. The breakout room feature worked really well based on participant feedback throughout the institute, but from an organizer’s perspective, a drawback is that you cannot see inside breakout rooms. In an in-person setting, it is easier to float from group to group just walking by to get a sense of how engaged participants are and how they are proceeding through the activities. In the virtual format, in order to “float” into a group, one has to actually enter the breakout room, which can be disruptive to participants.
An additional consideration for the future would also be to try to reduce the number of virtual platforms participants interact with during the institute. At some point during the institute, participants had to navigate between the SICSS curriculum website, the SICSS github pages, the SICSS-Rutgers schedule, the Slack general and rutgers channels, the Zoom link, and the SICSS-Rutgers curriculum page. While we tried to consolidate all of our curriculum to a single webpage landing, we found that some participants were confused by the numerous locations of materials. With more planning, we might be able to streamline all of the resources into a single location.
4. Week 2 (Group Projects)
The second week of SICSS-Rutgers was focused on group projects. Like SICSS-Duke, we used a google spreadsheet for people to add research interests. We had people fill it out over the weekend and during Monday morning. We then followed the research speed dating procedure to have people meet in two different groups to brainstorm project ideas. After the small group meetings, participants had about 30 minutes to sign up for a project. We recommended that people limit the size of the groups and had a soft rule of no more than 7 people. In the future, we might suggest reducing this to a maximum of 5 people to make it more likely that everyone can participate equally. We also did not have any firm rules about whether people could sign up for projects that they did not participate in developing. One could consider implementing a more moderated procedure for signing up for groups in the future. However, in general, this procedure worked well, and everyone stuck with their group for the remaining part of the week.
To maximize available group time for Tuesday-Thursday, we had groups check-in over Slack, only. On Tuesday, groups had to submit a short project plan. On Wednesday and Thursday, they had to provide one-paragraph updates on Slack. Most groups continued to meet in breakout rooms over the Zoom link, but we also had 1-2 groups each day that met separately. This decision was left up to groups to decide how to use their time. During small group time, we continued to have at least one organizer available in the “main room” for office hours support.
During this second week, we also provided a set of short, optional participant- or organizer-led tutorials on different topics, including ggplot (participant led), working with MTurk (participant led), loops in R, and web scraping. These were developed during the institute in response to participant suggestions and were well-attended.
On Friday we had eight group presentations. We required each person in a group to participate in some way during the presentations, and the groups abided by this. It was a terrific way to hear from each of our participants once more at the end of the institute. We were incredibly impressed by the quality and quantity of work that the groups were able to accomplish in such a short timeframe.
After the institute, we had very little we needed to do in terms of post-SICSS logistics. We indicated that we would continue to keep the Slack open for participants for as long as possible and provide an alternative platform if the Slack needed to be closed. We also encouraged participants to reconnect over group project ideas that they had proposed but ultimately did not work on during the second week. We also noted that we would follow up in the coming year to potentially organize an in-person or virtual meetup with participants.
5. Reflections on the Virtual Format
We found the virtual format allowed us to expand the number of participants. We were able to accept twice as many participants than we otherwise would have been able to if the event were held in person. Moreover, even with twice as many participants, the costs were less than if we had held the institute with half as many participants in person. We view this as a very important strength as it allowed the training to expand and be more inclusive of different levels of expertise and career stages. A second strength was that we were able to accept participants who absolutely would not have been able to attend if the event were held in person in New Brunswick, NJ (even without the pandemic). Our SICSS-Rutgers budget did not initially include funds that could cover travel and housing to New Brunswick. This likely would have prevented some participants from applying in the first place. We also had some participants remark that they appreciated not having to “put their lives on hold” for two weeks to travel to a location. This made it easier to manage attending the institute with other family and personal responsibilities, though likely also discouraged community-building outside of “standard SICSS hours.” While we did not have the time to take advantage of this in our institute, virtual institutes also create the potential to bring in speakers from more remote locations, potentially increasing the ability to have speakers from a wider range of personal and professional backgrounds.
However, the virtual format was not without weaknesses. As discussed in the First Week section, it was harder to engage in collaborative coding and troubleshooting virtually than it would be in person. Second, there was likely less energy to engage in non-research, more informal community-building, virtually. This potentially could inhibit the downstream ability of the institute to maintain its community without additional effort.
An additional weakness of having participants attend remotely was that while in theory, people could attend from all over the world, disparate time zones and connectivity issues make this incredibly hard in practice for participants who are attending from places far away from our location. We had a small number of participants attending from Europe and Asia, which made it more difficult for them to attend all events. One participant had to drop out of the institute after week 1 because of these issues. This suggests that if virtual institutes continue in the future in a more deliberately planned way, there might still be an impetus to “host” them in diverse locations across the world. Future funding might also consider how to make virtual events more accessible to individuals without robust home internet connections or for individuals that might require other accommodations.
SICSS-Stellenbosch organised by Richard Barnett and Douglas Parry
SICSS-Stellenbosch organised by Richard Barnett (SICSS-Cape Town 2018) and Douglas Parry (SICSS-Cape Town 2019) at Stellenbosch University in Stellenbosch South Africa. Additional support and experience was provided by Aldu Cornelissen (SICSS-Cape Town 2018), who is currently practicing computational social science in industry. As both Stellenbosch University and the South African Government took a proactive role in curbing exposure to COVID-19, SICSS-Stellenbosch was one of the first to be postponed due to the pandemic. After suitable consideration, we felt that it was possible to offer the programme virtually and with some restructuring brought the programme to life between 8 and 26 June 2020.
This post-mortem is broken down into the following sections: 1) advertisement, application, and
acceptance; 2) pre-arrival and onboarding; 3) the first week; 3) the second week; and finally, 4) the third week.
1. Advertisement, Application and Acceptance
Applications for SICSS-Stellenbosch were originally opened in February of 2020 with advertisement text having been sent to the heads’-of-department of major social science, computer science and information systems departments at universities in South Africa as well as a number of field-specific mailing lists and lists for postgraduate students in relevant degree programs. We also leveraged Twitter and past participants of SICSS-Cape Town for word of mouth advertising. We hoped and expected that this would lead to as much diversity in applications across South Africa. We did not actively expand our advertising into other parts of Africa as we were aware that our budget would not extend to bringing participants from further afield to Stellenbosch. To help ensure quality participants, we aimed to solicit applications with a letter of motivation attached to help identify the best candidates. We had intended to use Microsoft Forms for our application process, but discovered that it would not permit out-of-organisation users to submit files. We then settled on the use of Airtable as an alternative, which proved easy to use and effective. An early flurry of applications settled into a lull at about 15 applications around the time the COVID-19 crisis was unfolding in Italy and elsewhere in the world. As a proactive stance to the unfolding pandemic, Stellenbosch University banned the organisation and participation of all in person events through the end of June 2020 in early March. At this stage, we were forced to cancel our in-person event and immediately suspended applications.
Following due consideration at the primary SICSS-Duke site and our own internal evaluation, we reopened applications for an exclusively virtual event. Due to the transition to virtual, and tight timelines, we adjusted our expectations of the event and how we would run it. Having reopened applications, now asking for less detailed information from prospective participants, but adding questions on ability to connect virtually, we advertised the programme in the same manner as before. Given the delay caused by pausing applications and the consideration of a virtual event, we also extended our application deadline to 1 June 2020. With this deadline, we received a constant stream of applications and had to evaluate 85 applications to determine participation. With the benefit of hindsight, having the deadline so close to the start of the programme was a mistake, as some accepted participants were unable to participate due to the tight time constraint. Nevertheless, we accepted 22 participants and 15 of these were active throughout the programme.
The guiding principle we applied in accepting participants was based around the content of the restructured virtual event. We looked to accept participants where their background and CV suggested they would benefit from learning computational science skills, both technically and sociologically. To this end, we did not accept applicants who had career experience in data science and who’s CV suggested significant prior experience in R, or computational social science broadly interpreted. We also tried to give students who were starting out on their postgraduate studies more opportunity than those who had completed their studies or were close to doing so. Among the applications we had to reject were some from senior academics who felt that, as a growing field, computational science was something they should learn more about. While they were not a suitable fit for SICSS, we are engaging with them further to expand the field of computational social science in South Africa. We also decided to not accept any participants who were in time zones that were vastly out of alignment to our own. We felt that this was necessary to allow for better collaboration of the group. In the end, the vast majority of our participants were physically located in South Africa (but with nationalities from across Africa), with just a few from elsewhere in Africa (notably Nigeria and Kenya) and one who was based in Europe (Sweden).
2. Pre-Arrival and Onboarding
Due to the tight timeframe between acceptance and the start of SICSS-Stellenbosch, we did not require participants to do any preparatory work. In the days between acceptance and the start of the programme, we sought to obtain bios and photographs (for the website) from participants and to enrol them on the SICSS 2020 Slack. We used Slack as our primary communication too throughout the programme and have encouraged participants to continue using it into the future.
While Slack works particularly well, we did receive some feedback from a few participants that they were uncomfortable about the use of closed platforms such as Slack and especially Zoom. Zoom, particularly, was a cause of contention, given the negative exposure in the media. We additionally had a few technical problems with Zoom and in future years we will consider better alternatives, including possibly using Slack’s native calling functionality. Despite our short timeline, we managed to onboard participants in time for the start of the workshop and all participants were present in our first session.
3. Week 1 – Introductory Course in R
Based on our prior experiences at SICSS-Cape Town and our collective experience of two decades of teaching programming, we realised that the vast majority of applicants to SICSS-Stellenbosch were unlikely to have had much prior experience in R and that most will have had little formal experience with programming. While it has previously been a pre-arrival task for participants to learn R themselves, we felt that participants would benefit more from instructor led training in R than they would from self-study.
We kicked off our program with a live event the first morning for everyone to introduce themselves and for us to explain the structure of the program. The first week of the programme was dedicated to getting all participants up to speed in R, following the excellent book by Wickham and Grolemund: R for Data Science https://r4ds.had.co.nz/. This book, which is open access served to give structure to our instructor led training, which we presented via pre-recorded video lectures in the first week. Each day’s video lecture was accompanied by exercises from the book and textual discussion of the material on Slack. Throughout the day discussion took place on slack and, if necessary, one-on-one calls with participants too place.
To facilitate discussion participants were encouraged to post their code, errors, and successes on slack and respond to others’ questions.We held group calls each evening to catch up with participants and to debrief the day’s learning. We purposefully limited the synchronous video component of the programme to limit the difficulties from poor Internet connectivity, which can be prolific in South Africa. While we did not have major connectivity issues in the calls we did have, the glitches we did experience suggest that this was likely a good decision.
On Monday we focused on getting setup with R, RStudio, general good practices for project workflows, and programming in R. On Tuesday the videos and exercises focused on data manipulation with the tidyverse. The focus of Wednesday was working with tidyverse data sources, while Thursday focused on the core foundations of data analysis with different data types. Finally, Friday involved the foundations of data visualisation and introduced ggplot2 to the participants.
On most days the video content was between 45 minutes and two hours, with the exercises design to take another two hours depending on experience and skill level. On top of this we held an hour-long discussion each evening alongside the chats and calls on slack. All-in participants spent approximately six hours per day in the first week. For most this was manageable (with many using study leave for SICSS) but for some this was quite a lot to juggle in amongst other work and family-related demands at the time.
Feedback received from most participants was highly positive about the content of the first week, with many stating that this content is where they will benefit most in future. Most participants also indicated that this week’s content was necessary to prepare them for much of the content in week two. This feedback should be viewed as unsurprising, given that we knowingly accepted participants who we felt would benefit most from this content. Nevertheless, it was clear that participants were more readily able to engage with the content in week two than they had in prior years at SICSS-Cape Town.
4. Week 2 – Primary SICSS Content
In the second week, we aligned with the other SICSS locations and presented the content that was pre-recorded by Matt and Chris. We largely followed the suggested programme on Monday through Wednesday, where the content was relevant to our audience. On Thursday, we brought forward the content on experiments (from Saturday) and enhanced it with some of our own content on Git and on Social Network Analysis. We moved content from Saturday as we had previously decided to not use the weekends as part of the programme and that this content was relevant. We pushed the content on surveys from Thursday to Friday and dropped mass collaboration completely. This rearrangement was designed to try and alleviate fatigue on the Friday, and because the content on mass collaboration is not relevant to audiences where services such as Amazon Mechanical Turk are not available. In our attempt to alleviate fatigue, we appear to have introduced further fatigue, and by Thursday evening, most participants were behind in their progression through the videos and exercises.
It was particularly heartening for us to see the seriousness with which the participants engaged with the content on ethics, sparking significant discussion throughout the day, and with the debrief session running significantly over time. It was also exciting to see how the participants started applying the R skills and the trace data and text analysis content to their own fields and research.
The pre-recorded lectures proved to provide a better experience than had previously been possible at SICSS-Cape Town, due to the fact that they could be presented in the morning rather than starting only in the afternoon (due to the time-zone shift) and we would likely prefer these to live sessions for the same reason in future years. Collaborative work, as we expected, was severely impacted by the virtual nature of the event and we found it more practical to consider the programme an individual learning experience, with the collaborative aspects taking a backseat. We suspect that this may be some of the cause behind the fatigue as there was less scope for groups to work through problems together. Feedback on this second week largely revolved round the issue of fatigue and if we host SICSS again virtually, we will likely extend this content over a longer period.
5. Week 3 – Guest Lectures, Machine Learning and SICSS Festival
In anticipation of the difficulties in electronic collaboration, we always intended to not engage in group projects in the third week. We held two guest lectures of our own, presented some of our own content on machine learning and encouraged the participants to engage with the SICSS-Festival, which many of them did.
We presented two guest lectures, the first by Kyle Finlay, who has been performing computational analyses of South African politics on Twitter for some years. This talk served two purposes for our participants, the first to expose them to some interesting computational research, but also for them to see how computational techniques can be used to perform research in practice. The pre-recorded talk was followed by a live Q&A session and sparked some lively debate.
The second guest lecture was by Schalk Visagie, who spoke on the analysis of time-series data. Time- series analysis is a difficult topic, even for experienced researchers, and it is unsurprising that it proved to be difficult for many of our participants. We also presented some content on machine learning, which was somewhat delayed by some technical issues. This content was also taxing for some of the participants who are still getting used to programming. In future, we may reconsider these topics as we further consider our audience.
Several of our participants engaged with the SICSS-Festival to a greater or lesser degree, sometimes limited by the timing of events in relation to the time-zone differences. In future years, especially if the SICSS-Festival is continued, we might encourage more active participation through watching delayed recordings of such talks.
6. Concluding Remarks
Overall feedback received from participants was very positive and we are delighted to have been able to bring SICSS back to Africa. While we experienced a few technical glitches here and there, and made a few mistakes as we transitioned to virtual, we believe that our event was a success and we look forward to holding it again in future, either virtually, or as time allows, in person.
WICSS-Tucson
This is the post-mortem for the Winter Institute in Computational Social Science, hosted virtually by the University of Arizona between January 3-9, 2021. We have organized the post-mortem into three sections: 1) Promotion, Selection, and Onboarding, 2) Main Event, and 3) Participant Feedback.
1. Promotion, Selection, and Onboarding
We initially planned to host an in-person event that would include between 20-30 participants. As the other 2020 SICSS sites started canceling or moving their site to a virtual format to slow the spread of the novel coronavirus, we were fortunate to be able to delay our decision because our site would take place over Winter (in 2021) rather than Summer. We eventually made our decision to move to a virtual format too after consulting with several folks at the University of Arizona and the main SICSS organizers Chris Bail and Matthew Salganik.
We promoted the event on Twitter on several occasions throughout 2020, starting with the initial announcement of the SICSS partner sites in January. We did a second round of promotion in April once opening up the application process, which initially had a deadline of July 1st. We had a third round of promotion before that deadline in late June, after the completion of the main SICSS site at Duke. We did not end up receiving many applications before the July 1st deadline, likely because 1) the event was still several months away and 2) the pandemic made it difficult for people to make plans far in advance.
In September, we decided to extend the application deadline to November 1st and promoted the new deadline on Twitter. One week before the new deadline, we promoted the event on Twitter one last time, announcing the speakers that we had lined up for the week. We also reached out to departments at the University of Arizona and Arizona State University to solicit their help in promoting the event. Finally, we posted the event on several academic listservs. This was an effective method, but possibly shaped the composition of our applicant pool. A high proportion of our applicants, and consequently our participants, were housed in political science departments. In the end, we received just under 100 applications, including a few duplicates.
To select the final set of participants from the application pool, each of the organizers went through the list of applicants on their own and scored each applicant as No/Yes/Maybe. The applicants’ CV, research statement, and writing sample were used to make these decisions. The organizers met twice to calibrate our criteria, compare scores, and decide on the final set of participants. Several applicants were excluded because they had previously participated in other SICSS sites. Another topic of discussion during these meetings was the possibility of increasing the set of participants beyond the initial limit of 30. This was one of the most significant advantages of having a virtual site, since it allowed us to include a larger and more diverse set of participants. We decided to limit our pool to 45 participants because we were concerned that 1) it would be difficult for us to manage a larger group and 2) it could make it challenging for participants to form meaningful connections with one another. In the end, we accepted 45 participants, 41 of whom ended up attending the institute.
Of those who accepted, 22 reported identified as female (54%), one as non-binary, and 18 as male. 19% of our applicants were from universities outside of the United States. Several different disciplines were represented among our participants, including social work, information science, business, and environmental studies. Political science (44%), sociology (12%), and communications (10%) were the largest groups. The majority of participants were graduate students (78%). Four Junior faculty members and four post-docs made up the remainder of the participants.
After confirming with the speakers about providing sessions for WICSS-Tucson, the organizers set up virtual meetings with the speakers to discuss the contents and scope of what they would present. The organizers also set up a Google Drive folder where speakers could upload any slides, readings, and code that they planned to use during their sessions. One of our site’s TAs went through the code, all of which was in R, and attempted to run it and produced an introductory script that we shared with participants about 10 days before the institute began. We asked our participants to run this script to ensure that all necessary packages were installed before the institute and that they obtained the necessary API authentications in advance. Our site’s other TA created links on Zoom and Wonder that we would use for the main event. We sent an email to accepted participants with information to help them prepare, including a link to the SICSS-Bootcamp tutorials.
2. Main Event
The Winter Institute began with a virtual meet-and-greet on January 3rd. The meet-and-greet included four 15-minute sessions where participants were randomly divided up into Zoom breakout rooms of 3 or 4 people. Both organizers and both TAs attended the meet-and-greet along with several of the week’s speakers and a large majority of the site’s participants. The idea to have a meet-and-greet was the product of an initial meeting between the organizers and the TAs to plan the site. Both TAs had attended SICSS-Duke virtually over the summer and suggested adding a meet-and-greet, which turned out to be a great idea.
The week included guest speaker sessions, research roundtables where participants discussed their own ideas, a keynote, a virtual social event, and breaks. The guest speaker sessions and keynote were held over Zoom, while the research roundtables and breaks were held over Wonder. The virtual social event used both platforms. Switching between platforms went pretty smoothly, though a couple of participants reported having issues with Wonder. The morning of the first day included brief introductions by all of the participants, which ended up taking longer than expected by about half an hour. All of the guest speakers for the day were informed and accommodated the time change. However, this longer morning did not include any breaks, something that came up in the daily survey that we corrected on the following days.
Later in the week, two of the guest speaker sessions also went longer than expected. When it was time to switch to the next activity, we polled participants to gauge whether they wanted to continue with the session or move on to the next activity (a research roundtable). Both times, a majority of participants voted to continue with the session, though a sizable minority voted for the research roundtables. In the end, we went with the majority and continued with the guest speaker sessions, though some participants reported wanting more research roundtables in the survey that we sent out at the end of the week. In hindsight, we could have set up two tracks, one for continuing the guest speaker sessions (on Zoom) and another for the research roundtables (on Wonder).
All in all, participants were engaged throughout the week. The organizers and TAs used Slack and private chat over Zoom to make adjustments in real-time, while also accommodating more structural program changes (more breaks, fewer research roundtables) through the daily surveys and Zoom polls. Because the event was held over Winter break, there was only enough time for a single week’s worth of activities. While the institute provided participants with opportunities to learn and socialize with each other at a unique time of the year for SICSS, the event was shorter and did not offer as many opportunities for participants to apply what they learned (as other sites typically do in the second week). This tradeoff is important to consider for other sites that are planning to host a Winter institute.
We found there to be clear costs and benefits of a virtual site. Starting with the benefits, the format allowed us to admit a larger, more diverse pool of applicants than originally anticipated. We did not have to spend any time dealing with logistics and other issues that might arise in an in-person event. This allowed the organizers and TAs to focus their attention on developing the materials and interacting with the participants. There are costs to having a virtual site, including difficulty networking with others in more informal ways and research discussions not translating too well in an online space.
3. Participant Feedback
We conducted daily surveys to get feedback from our participants about how we could improve the site. We used the same format as prior SICSS daily surveys. Each day the organizers and the TAs met before the first session to discuss the survey responses and to talk about any changes we wanted to make. We received a total of 41 responses over the week. Additionally, we sent out a survey at the end of the event. We received 20 responses for this final survey (49% response rate).
In general, participants reported having a very positive experience. They reported learning a lot of new content, enjoying the lectures, and appreciating the opportunity to interact with one another. They also highly valued the help from the two TAs.
Below is a summary of the issues raised by participants, how we addressed them, and some takeaways that may help future sites.
-
We didn’t have enough breaks in our schedule. Several participants raised this issue and we addressed it by adding 10-minute breaks into longer sessions. Participants appreciated this change.
Takeaway: Ensure there are frequent breaks in the online schedule.
-
The breaks also provided a valuable opportunity for interaction between participants. While some were a little confused by Wonder at the beginning, several remarked that they enjoyed the more informal structure of the exchanges. One issue that made interactions more difficult was differences in time zones. By the time we finished for the day, it was very late in Europe and locations further to the east, so some participants in these locations tended not to join the end-of-the-day activities.
Takeaway: Provide ample opportunities for networking in online events. Consider spacing these out at different times if people from multiple time zones are participating.
-
We organized research roundtables, where participants could discuss their research ideas in small groups. The feedback on these was mixed. Some participants valued the experience and wanted more of it, while others did not like the discussion’s directed nature and preferred more “organic” interactions.
Takeaway: If we organized this event in the future, it might be better to give participants the option of either engaging in a more focused discussion (e.g., discussing research ideas, giving short flash talks) or having the chance to socialize more informally.
In addition, some participants also requested more moderation of the research roundtables. Overall, this format needs more work to be effective in an online setting.
-
We did not systematically record sessions, assuming that folks would participate synchronously. We recorded some workshops when requested. A couple of participants noted that they appreciated the recordings. For example, one mentioned using the recordings to catch up due to a bad internet connection.
Takeaway: Determine a recording policy in advance and be consistent.
SICSS-UCLA
This is the post-mortem for the SICSS 2020 partner site hosted by UCLA. The institute took place from June 15 to June 26. We provide a brief summary of the different stages of the institute as well as our impression about what went well and what we would try to improve in the future.
1. Outreach, Application and Planning
Compared to SICSS 2019, our outreach began earlier and we cast a far wider net (e.g., to more departments and centers across more universities in Southern CA). We also kept track of these outreach efforts more systematically in a google sheet. We organized SICSS-UCLA 2019, and so we already had a list of where we reached out to in 2019, but organized and added to this list for.
Our application consisted of a Google Form, which we copied and improved from SICSS-UCLA 2019 and is very similar to the main site’s form. We intentionally did not ask for letters of recommendation this year or last year, to reduce the overhead for applicants. Compared to SICSS-UCLA 2019, we also tried to convey clearer expectations for the statement of purpose. We felt that Google Forms was a smooth platform to use for applications in both years. Much like last year, our website stated that we were going to focus on causal inference and machine learning, which did seem to influence the applications we got.
Unsurprisingly, our application (and planning) process was hindered by the onset of COVID-19. Initially, we had fewer applicants than expected, and so we extended our deadline. Given the growing uncertainty about whether SICSS (the main site, and our site) would occur, and how it would occur, we held off on reviewing the applications, planning a schedule, and inviting speakers until we had a better idea about how to proceed. Once we were sure that SICSS-UCLA would be online, we decided to limit our cohort to a small number to preserve the community feel of SICSS (we accepted around 30 applicants, and correctly expected some attrition). Our participants were largely in the same time zone, and we intentionally tried to accept a cohort in Southern CA with the hopes that collaborations would be more likely to continue after SICSS. In general, we also realized we had to be more flexible, scale down our schedule, and expect new challenges in SICSS-UCLA 2020.
2. Pre-arrival and Onboarding
Our onboarding felt disorganized compared to last year; this was partly due to the new challenges of SICSS-2020 in general (e.g., a late start on planning, our own uncertainty about how to effectively run the institute online which meant we spent a longer time finalizing a schedule). We tried to keep emails to participants to a minimum, and include more information in each email, but there were still a lot of small details and tasks for participants (and us) to keep track of, and many of these details were conveyed to participants later than we would have liked.
We wanted participants to be able to get to know each other before the institute began, especially since it was online. We used two tactics. First, we had participants fill out a Google Sheet (which they could update through the week, and all see each others’ entries) with their name, email, interests, and project ideas. Second, we also asked participants to introduce themselves on Slack when they joined. In hindsight, we should have emailed participants Slack information farther ahead of time (like, a month) so they would have had more time to start posting, getting to know each other, and using it. If we do SICSS online in the future, figuring out how to encourage and provide more opportunities for participant networking is something we could improve.
We spent a lot of time thinking about ideal ways to schedule SICSS-UCLA 2020 over Zoom, but this also meant our schedule wasn’t finalized until the last minute, and so we posted the schedule online later than we would have liked. In the end, we think this schedule worked well for this year’s situation, and would follow a similar schedule in hindsight.
3. Week 1
Last year, the first week of SICSS-UCLA had a mix of lectures and group activities. This year, we tried to adapt to the online format while preventing zoom fatigue, like the main site. We asked participants to watch several specific videos from the main site ahead of time (these were great videos!), we had limited lecture time (aiming for max 2 hours per day, broken up and with varying speakers throughout the day), added a long break in the middle of the day, and set aside a lot of time for break out rooms in Zoom.
Monday through Thursday, we had lectures in the morning about the topic of the day (led by an organizer who is specialized in that topic), a small group activity in break out rooms, and then a guest lecture in the afternoon. In light of our own interests, we stuck to the lectures and activities for digital trace data, text analysis, and ethics, but supplemented the lectures on text analysis with a broader focus on unsupervised learning and word embeddings. Like last year, we also spent two days using our own activities and lectures on supervised ML and causal inference. This is a tough tradeoff because our applicants express explicit interest in CI and ML, but in practice often are very interested in online surveys and experiments for their collaborations. We really appreciated the expanded online content on these topics this year, and luckily had a speaker use their talk to provide an overview on how to conduct online experiments in the context of their own work.
We did lectures live and specifically for our site, since we thought this would foster a more interactive learning environment, and we could leverage the organizers’ own knowledge in computational social science topics. Overall, we thought this structure for the first week went well, although we did find it difficult to get used to Zoom (and we found the breakout rooms clunky to use even when we got the hang of them). In particular, the inability for more than one organizers to move seamlessly between breakout sessions to check in with groups was really frustrating.
We found that it was more difficult to gauge participants’ engagement and level of understanding over Zoom, especially because many had their cameras turned off. It was often unclear whether participants were quiet because material was too simple, or too advanced, or for other reasons. Ideally, lectures would be more interactive and perhaps explicitly more discussion based. When there were discussions intermittently through lectures (whether prompted by lecturer or by participants’ questions), they were really fruitful. The online format also made instruction difficult because we could not have side conversations which are often very useful to explain concepts in different ways, ask questions in a more informal format, or go in depth into an interesting tangent.
On Friday, when we covered ethics, rather than a guest lecture, we hosted a panel bringing together three guest speakers specializing in ethics and artificial intelligence (AI). We thought this went extremely well: it was relevant, fascinating, and participants were very engaged. It also worked really well online, since we could bring panelists together from across the country. It was also more interactive compared to lectures. We highly suggest this type of panel format again in the future, whether in-person or online (especially for a topic like ethics and AI, which is important and has a lot to discuss right now). In the future, on the day we discuss ethics we would also have a short, full group discussion to ensure participants were on the same page about IRB requirements for the group projects at UCLA (we later emailed this out to participants).
The first week, we also hosted office hours on Monday and Wednesday afternoon, which were somewhat attended. We also used slack heavily (as did participants), to direct message with individuals, groups (those in group projects), and message everyone. Last year we didn’t use Slack much, and this year not only did SICSS-UCLA use it a lot more, but (we think) it also enabled a community feel of SICSS-UCLA despite being online.
4. Week 2
The second week of SICSS was geared towards group projects, and we also anticipated that participants would attend the optional SICSS Festival. We also invited participants to give flash talks on Monday of the second week (on their own work, or on their project ideas), and asked everyone to attend even if the presentation was optional. Despite our encouragement we only had one volunteer give a flash talk. Our volunteer did an excellent job and their presentation sparked a very fruitful discussion. We additionally had two required check-in meetings with groups through the week.
We asked participants to email us their group project ideas (and who was in their group) by Monday end of the day. Some emailed us, but others either emailed later in the week (and wanted to work alone), and others we followed up with did not reply. This was reflective of group projects in general – some groups (and some participants) were very enthusiastic about conducting a project (and wanted to continue collaborating beyond the second week), while others disengaged. We saw this in SICSS-2019 as well. In the future, we would like to think of more effective strategies to keep participants engaged in the second week and in projects in general. We would also be more explicit to potential applicants that the second week is focused on group projects. We explicitly encouraged group projects, but this year also let participants do their own projects if they strongly preferred to do so (which quite a few did, for varying reasons). We were concerned that participants would have a hard time forming groups, since this is already logistically difficult offline and even more so online. However, we were happy to observe that participants used slack, zoom, and other methods successfully and independently to form group projects. By the end of week, I think we had at least 4 groups of 2-4 people actively collaborating.
Unlike last year, we did not have required flash talks for group presentations at the end of the two weeks, since we felt this would be a lot more zoom time in a big group. Instead, we asked each group to schedule a check-in with an organizer on Wednesday afternoon and then again on Friday afternoon (with different organizers). These check-ins were times for the group to update the organizer on their idea, ask questions, get feedback and ideas. This went smoothly and we think that it helped keep momentum going the second week and provided a really useful time for participants to learn more informally. We would do this again in hindsight (even if not online). Some participants asked if we could informally meet as a big group again in a few weeks, when they had more progress on their projects and results to show others in SICSS-UCLA. We thought this was a great idea.
We were a bit unclear around using the Mturk funds, and so in turn participants were unclear about how they could use these. Specifically, in the future it would be useful if we were clear to participants (as early as possible) about available funds, ways to use Mturk, how to use it, and when they had to use the money. For example, one group wanted to apply for IRB approval first over the few weeks following SICSS and then run their experiment, so that they could publish a paper with it. At the same time, we think that having the opportunity to use Mturk funds is a fantastic and motivating opportunity for participants to carry out project.